2023年1月現在、AIアプリケーションによってノーコードで絵を生成するアプリがいくつか存在します。
その中でも特にメジャーである2つのAI絵画生成アプリを紹介し、拾えるところまで活用技術やその原理
を追ってみます。
(それぞれのアプリの使い方は紹介しません…ご了承ください。)
1.DALL-E
手軽にお試ししたい方は https://huggingface.co/spaces/dalle-mini/dalle-mini でノーコードかつ無料で
ご利用いただけます。(ここでは使ってみての感想等は触れない方向でいきます)
まずはDALL-Eとはなにか、というところから述べ、画像生成までのIT技術を触れられるところまで
触れます。
1.1 DALL-Eとは
DALL-E (DALL·E)及びDALL-E 2は、OpenAI(※)で開発されたディープラーニングモデルを使用しており、
自然言語で定義づけられた”プロンプト”からデジタル画像を生成する機能を持つアプリケーションである。
—OpenAIとは—
アメリカの営利または非営利団体のグループをひとまとめにした総称、らしいです。
1.2 DALL-Eを支える技術について
DALL-Eを支える技術について述べるためには、ディープラーニング技術について少々押さえておく
必要があります。
パッと浮かんだキーワードだけでも下記のようなIT技術が存在し、非常に難解です。
よって、ここでは概要だけを述べ、詳細は別記事にて触れることといたします。
DALL-Eを支える技術のキーワード(別記事にて詳細を解説します)
- 【GPT】Improving Language Understanding by Generative Pre-Training
→論文はこちら。 - 【GPT2】language models are unsupervised multitask learners
→論文はこちら。 - 【GPT3】Language Models are Few-Shot Learners
→論文はこちら。 - CLIP (Contrastive Language-Image Pre-training)
→論文はこちら。 - Diffusion Model
→論文はこちら。
(上記いずれの論文も無料で公開されていますので、引用させていただきました)
DALL-Eを支える技術についての概要
主に自然言語処理(NLP)やコンピュータビジョン(CV)の分野で利用されている、入力データの各部分の重要度を差分的に重み付けするSelf-Attentionの仕組みを採用した深層学習モデルのTransformアーキテクチャ
を用いて、OpenAIで2018年に開発されたモデルがGPTです。GPTはGPT-2へ2019年にスケールアップされ、
更に2020年にはGPT-3にスケールアップされました。これにより、1750億のパラメータを用いたモデル
へと進化し、DALL-Eのモデルではインターネット上のテキストと画像のペアで学習した、120億個のパラメータを持つGPT-3のマルチモーダル実装で、「テキストのピクセルへの変換」を実現しています。なお、
DALL-E 2は35億個のパラメータを使用し、前モデルよりも数が少なくなっています。
DALL-EはCLIP (Contrastive Language-Image Pre-training) とGPTとで共に開発され、一般に発表されまし
た。CLIPはzero-shot learning に基づく別モデルであり、DALL-Eはインターネットから集めたテキストキャプション付きの画像4億組で学習した。CLIPでは、データセットからランダムに選んだ32768個のキャプション(うち1つは正解)からどのキャプションが画像に最も適しているか予測し、DALL-Eの出力を「理解しランク付け」します。このモデルは、DALL-Eが生成したより大きな初期画像リストをフィルタリングして、最も適切な出力を選択するために使用されています。
DALL-E 2では、推論時にCLIPテキスト埋め込みから事前モデルによって生成されたCLIP画像埋め込みを条件とした拡散モデル(Diffusion Model)を用いています。
・・・というのがDALL−Eのテクノロジー的概要ですが、これだけでは専門知識がないと理解できませんね…
よって、ぜひ別記事とはなりますが、DALL-Eを支える技術のキーワードのそれぞれについて詳細に学習して
いきますので、そちらをご覧いただいた後に再びこの記事に戻って理解度を深めていただければ幸いです。
2.Midjourney
Midjourney公式ページ:https://midjourney.com/home/?callbackUrl=%2Fapp%2F
Midjourneyの利用は、従量課金性に近い料金形態となっており、無料での利用には描画枚数制限がありま
す。こちらはDALL-Eと異なり、どのようなIT技術を用いているのかが公開されておらず、中身の技術がブラッ
クボックス化しています。だが、ただ一つ言えることはDALL-Eとは異なる描画アーキテクチャが使われている
ようで、DALL-Eと比較して詳細まで鮮明に描画されており、Midjourneyの方がより人間らしい画風になりま
す。
それではMidjourneyで描画した図をご覧ください。

上の図はMidjourneyで描画した絵画であり、なんとアメリカ コロラド州で開催されたファインアートコンテストで1位を取得しました。この件については多くの議論が未だなされていますが、「芸術はAI技術で表現できる」(AI自身がそれを意識していなくとも、一般人をアーティストへと導けるだけの力がある)ことを
示した、人類及びAIの歴史的出来事だと私は思います。
3.AIで生成されたモノには著作権があるのか?
上述のMidjourneyで描画した絵画をこのHPで公開していますが、「著作権に反しているのか」について
本章で述べます。これに対する議論は多くされており、「AIの著作権について」(内閣官房知的財産戦略推進事務局)として2018年と少し古いが、AIと著作権の考え方について定義がなされました。
詳細は下図をご覧ください。
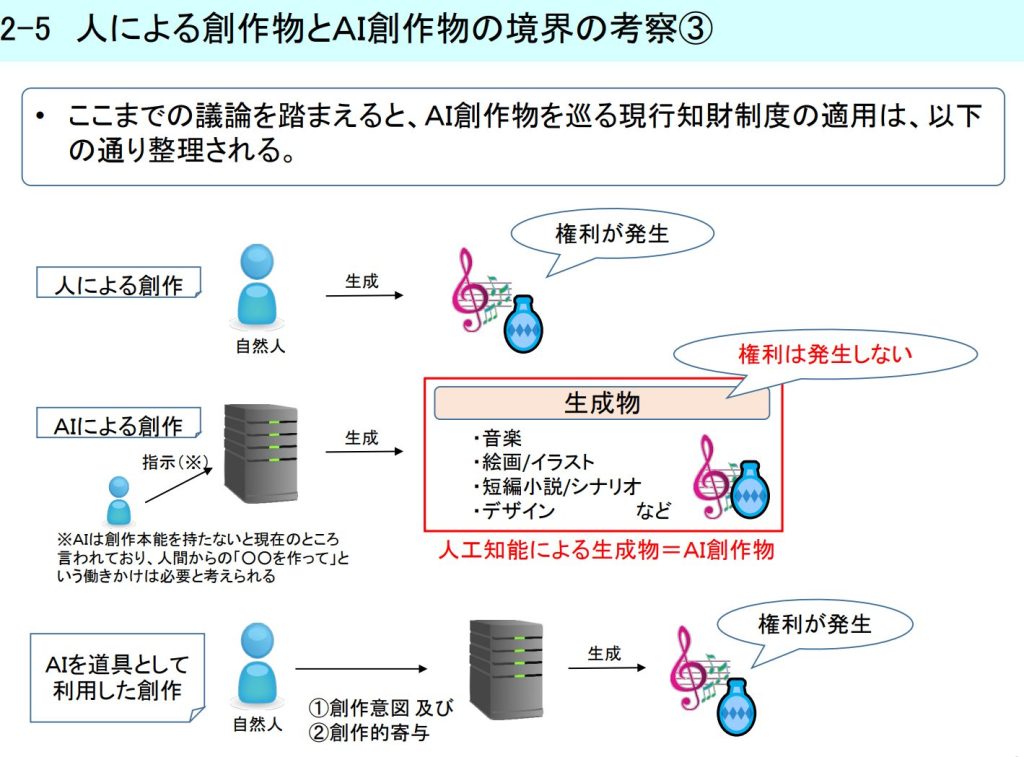
上図のように定義されてはいますが、私にはまだライン引きがまだ曖昧であると感じています。
よって、あくまで私個人が定義をどのように考えていることを述べた後に、著作権に反しているかを
考えます。
結論から言えば、Midjourneyでの絵画の描画は「人間がMidjourneyにプロンプトという命令を
実行して得られた生成物であり、その生成物の2次使用を想定していない」とし、図の中段のカテゴリ
に該当する、というのが私の見解です。(間違っていましたらメンションいただけますと幸いです)
よって、正直グレーですがここで紹介した図は著作権を犯していないと考えております。