本記事では、こちらの論文で記載されているPGGAN技術について論文を和訳する形で学習していきます。
1.概要
この論文は、高解像度の画像を生成するための新しいGANアーキテクチャ「Progressive Growing of GANs(PGGAN)」を提案しています。PGGANは、解像度を徐々に増やしながらトレーニングすることで、高品質な画像を生成することができます。また、著者らは、MSSSIMという新しい評価指標を提案し、小さな効果にも敏感であり、トレーニングセットとの類似性に基づいて画像品質を評価することができることを示しました。実験結果から、PGGANは従来のGANよりも高品質な画像を生成することができることがわかりました。しかし、現在のGANには改善すべき課題(*)が残っており、今後も研究が進められる必要があります。
*GANの解決すべき課題:
1. セマンティックな感性やデータセット固有の制約を理解する能力の改善
2. 画像のマイクロ構造の改善
3. データセットサイズへの依存性
4. 評価指標の改善
これらの課題に対処することで、より高品質な画像を生成することができるようになると期待されています。
2. PROGRESSIVE GROWING OF GANS
Progressive Growing of GANs(PGGAN)は、高解像度の画像を生成するための新しいGANアーキテクチャです。PGGANは、低解像度の画像から始めて、徐々に解像度を増やしながらトレーニングすることで、高品質な画像を生成することができます。この方法により、トレーニングプロセスは大規模な構造から始まり、徐々に微細な構造に移行することができます。また、PGGANでは、新しい層をスムーズにフェードインさせることで、ネットワーク全体をトレーニングする必要がありません。これにより、トレーニングプロセスがより効率的になります。実験結果から、PGGANは従来のGANよりも高品質な画像を生成することができることがわかっています。
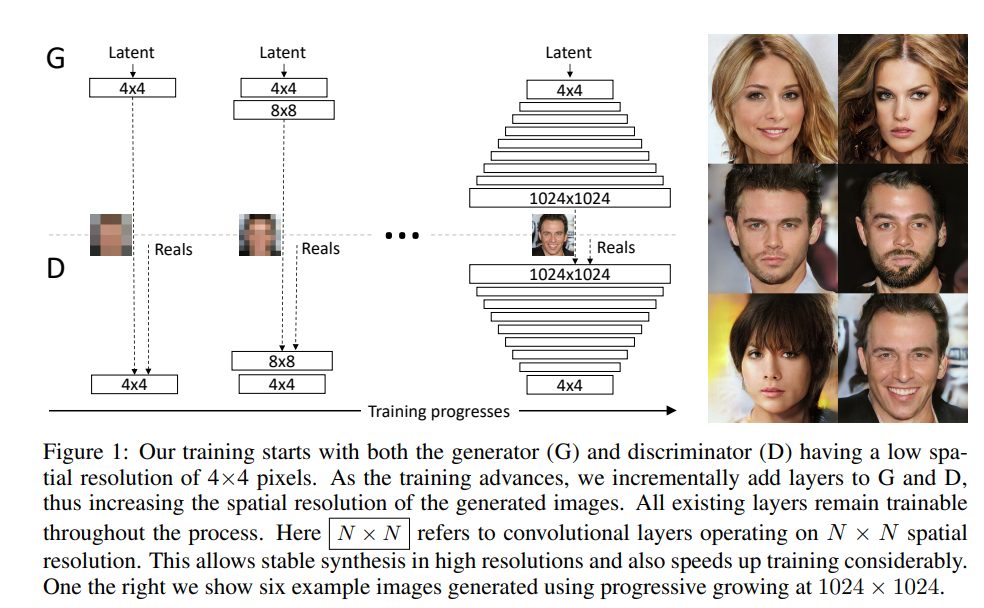
3.INCREASING VARIATION USING MINIBATCH STANDARD DEVIATION
Increasing Variation Using Minibatch Standard Deviationは、GANがトレーニングデータの一部のバリエーションしか捕捉できない傾向があるため、Salimansらは「minibatch discrimination」という解決策を提案しました。これは、個々の画像だけでなく、ミニバッチ全体から特徴量統計を計算することにより実現されます。これにより、生成された画像とトレーニング画像のミニバッチが類似した統計情報を示すようになります。この方法は、ディスクリミネーターの最後にミニバッチレイヤーを追加することで実装されます。このレイヤーでは、入力アクティベーションを統計配列に投影する大きなテンソルを学習します。各例ごとに別個の統計情報が生成され、出力に連結されるため、ディスクリミネーターは内部的にこれらの統計情報を使用することができます。
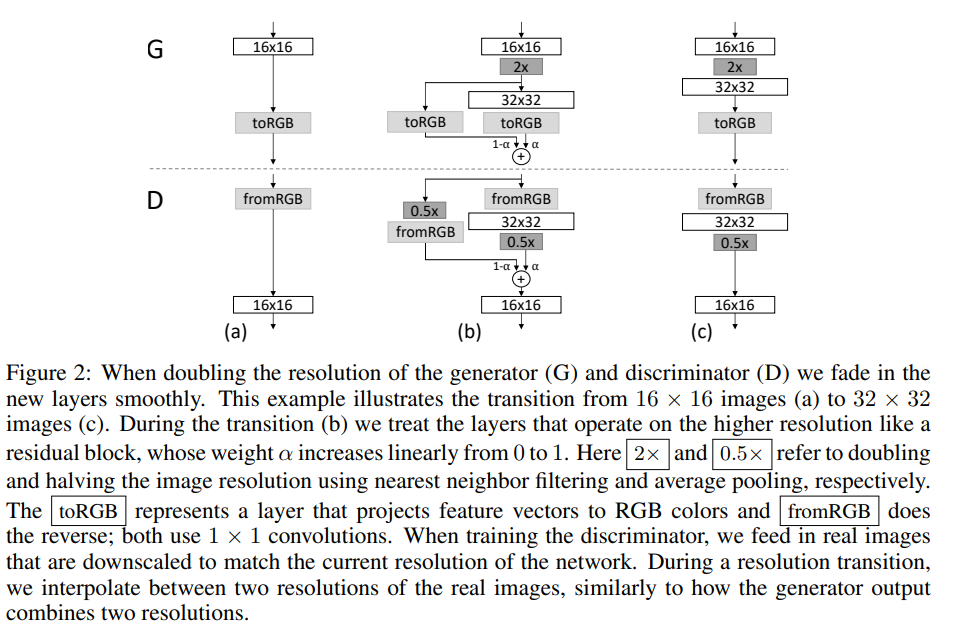
4.NORMALIZATION IN GENERATOR AND DISCRIMINATOR
4.1 EQUALIZED LEARNING RATE
Equalized Learning Rateは、GANのトレーニングにおいて、重みの初期化に注意を払う代わりに、単純なN(0,1)の初期化を使用し、実行時に明示的に重みをスケーリングする方法です。具体的には、Heの初期化子(He et al.、2015)からのレイヤーごとの正規化定数cを使用して、ˆwi=wi/cとして重みをスケーリングします。これは、RMSProp(Tieleman&Hinton、2012)やAdam(Kingma&Ba、2015)などの一般的に使用される適応型確率的勾配降下法で用いられるスケール不変性と関連しています。これらの方法では、勾配更新をその推定標準偏差で正規化するため、パラメーターのスケールに依存しないようにします。
4.2 PIXELWISE FEATURE VECTOR NORMALIZATION IN GENERATOR
Pixelwise Feature Vector Normalization in Generatorは、競合によってジェネレーターとディスクリミネーターの大きさが制御不能になる状況を防ぐために、ジェネレーター内の各ピクセルの特徴量ベクトルを畳み込み層ごとに単位長さに正規化する方法です。これは、「local response normalization」(Krizhevsky et al.、2012)の変種を使用して行われます。具体的には、a(x,y)とb(x,y)がそれぞれピクセル(x,y)での元の特徴量ベクトルと正規化された特徴量ベクトルである場合、
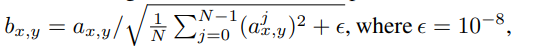
を使用します。ここで、ε=10^(-8)であり、Nは特徴マップの数です。
5. MULTI-SCALE STATISTICAL SIMILARITY FOR ASSESSING GAN RESULTS
Multi-Scale Statistical Similarity for Assessing GAN Resultsは、GANの結果を比較するために、大量の画像を調査する必要があるため、自動化された方法に頼ることが望ましいと考えられています。既存の方法であるMS-SSIM(Odena et al.、2017)は、大規模なモード崩壊を信頼性高く検出できますが、色やテクスチャのバリエーションの損失などのより小さな効果に反応できず、トレーニングセットとの類似性に基づいて画像品質を直接評価することはできません。そこで、本手法では、異なるスケールで画像を比較し、トレーニングセットとの類似性を評価します。具体的には、異なる解像度で生成された画像ペア間の多尺度SSIM(Wang et al.、2003)値を計算し、それらを組み合わせてGANの品質を評価します。
6.DISCUSSION
Discussionでは、GANの結果の品質について議論されています。結果は一般的に以前のGANの研究と比較して高品質であり、大規模な解像度でもトレーニングが安定していますが、真の写真のようなリアルさにはまだ遠く、セマンティックな感性やデータセット固有の制約(例えば、あるオブジェクトが曲線ではなく直線であること)を理解する能力に欠けています。また、画像のマイクロ構造にも改善の余地があります。しかし、CELEB A-HQでは説得力のあるリアルさが実現可能であると考えられています。