本記事では、こちらの論文で記載されているDCGAN技術について論文を和訳する形で学習していきます。
1.概要
この論文は、Deep Convolutional Generative Adversarial Networks(DCGANs)という画像生成モデルについての研究を報告しています。DCGANsは、畳み込みニューラルネットワークを用いた敵対的生成ネットワーク(GAN)の一種であり、高品質な画像生成が可能であることが示されています。 本論文では、DCGANsのアーキテクチャやトレーニング方法について詳細に説明しています。また、DCGANsが教師あり学習タスクでも優れた性能を発揮することが示され、学習された特徴表現が一般的な画像表現としても適用可能であることが示唆されています。 さらに、本論文ではDCGANsの内部構造を調査し、可視化する方法についても説明されており、高品質な画像生成に役立つアドバイスも提供されています。 最後に、本論文では今後の研究方向についても提案されており、DCGANsをより広範囲な応用分野に適用し、その性能をさらに向上させることが期待されています。
2.RELATED WORK
2.1 REPRESENTATION LEARNING FROM UNLABELED DATA
”Representation Learning from Unlabeled Data”は、教師なし学習における表現学習の問題について説明した論文です。一般的なコンピュータビジョンの研究や画像の文脈で、教師なし表現学習は比較的よく研究されています。教師なし表現学習の古典的なアプローチは、データ上でクラスタリングを行い(例えばK-meansを使用)、クラスターを利用して分類スコアを改善することです。画像の文脈では、画像パッチの階層的クラスタリング(Coates&Ng、2012)を行うことで、強力な画像表現を学習することができます。
2.2 GENERATING NATURAL IMAGES
”Generating Natural Images”は、自然画像の生成に関する研究について説明した論文です。この論文では、MNIST数字やテクスチャ合成(Portilla&Simoncelli、2000)などの例を挙げながら、パラメトリックモデルを使用した画像生成の研究が広く行われていることが述べられています。しかし、現実世界の自然画像を生成することは最近まで成功していませんでした。論文では、Kingma&Welling(2013)による変分サンプリングアプローチが一定の成功を収めたものの、生成されたサンプルはぼやけているという問題があることや、Sohl-Dicksteinら(2015)による反復的な前方拡散プロセスを使用したアプローチもあることが述べられています。また、Goodfellowら(2014)によるGenerative Adversarial Networks (GANs) はノイズや理解不能な画像を生成する問題があったことも報告されています。
2.3 VISUALIZING THE INTERNALS OF CNNS
”Visualizing the Internals of CNNs”は、畳み込みニューラルネットワーク(CNN)の内部を可視化する方法について説明した論文です。CNNは、画像認識や画像生成などのタスクで広く使用されていますが、その内部構造がブラックボックスであるため、どのように機能しているかを理解することが困難でした。 この論文では、Zeilerら(Zeiler&Fergus、2014)によって提案された手法を紹介しています。この手法では、逆畳み込みと最大活性化フィルタリングを使用して、各畳み込みフィルターの近似的な目的を見つけることができます。同様に、入力に対する勾配降下を使用することで、特定のフィルターのサブセットを活性化する理想的な画像を調べることができます(Mordvintsevら)。これらの手法により、CNN内部の動作や機能に関する洞察が得られるようになりました。
3.APPROACH AND MODEL ARCHITECTURE
”Approach and Model Architecture”は、Deep Convolutional Generative Adversarial Networks(DCGANs)という画像生成モデルについての研究を報告した論文です。DCGANsは、畳み込みニューラルネットワークを用いた敵対的生成ネットワーク(GAN)の一種であり、高品質な画像生成が可能であることが示されています。 本論文では、DCGANsのアーキテクチャやトレーニング方法について詳細に説明されています。従来のCNNを使用した画像生成ではうまくスケールアップできなかった問題を解決するため、低解像度の生成画像を反復的に拡大する手法が提案されました。また、教師あり学習タスクでも優れた性能を発揮することが示され、学習された特徴表現が一般的な画像表現としても適用可能であることが示唆されています。 さらに、本論文ではDCGANsの内部構造を調査し、可視化する方法についても説明されており、高品質な画像生成に役立つアドバイスも提供されています。最後に、今後の研究方向についても提案されており、DCGANsをより広範囲な応用分野に適用し、その性能をさらに向上させることが期待されています。
4.DETAILS OF ADVERSARIAL TRAINING
”Details of Adversarial Training”は、Deep Convolutional Generative Adversarial Networks(DCGANs)のトレーニング方法について説明した論文です。DCGANsは、敵対的生成ネットワーク(GAN)の一種であり、高品質な画像生成が可能であることが示されています。 本論文では、LSUN、Imagenet-1k、および新しく作成されたFacesデータセットを使用してDCGANsをトレーニングする方法について詳細に説明されています。また、トレーニング中に発生する問題やその解決策についても説明されています。例えば、モード崩壊と呼ばれる現象が発生しやすくなる問題に対しては、ジェネレーターとディスクリミネーターの学習率を調整することで解決策を提供しています。 さらに、本論文ではDCGANsのアーキテクチャやトレーニング方法の改善点についても言及されており、より高品質な画像生成を実現するための提案が行われています。これらの改善点は、「Remove fully connected hidden layers for deeper architectures.」、「Use ReLU activation in generator for all layers except for the output, which uses Tanh.」、「Use LeakyReLU activation in the discriminator for all layers.」などです。
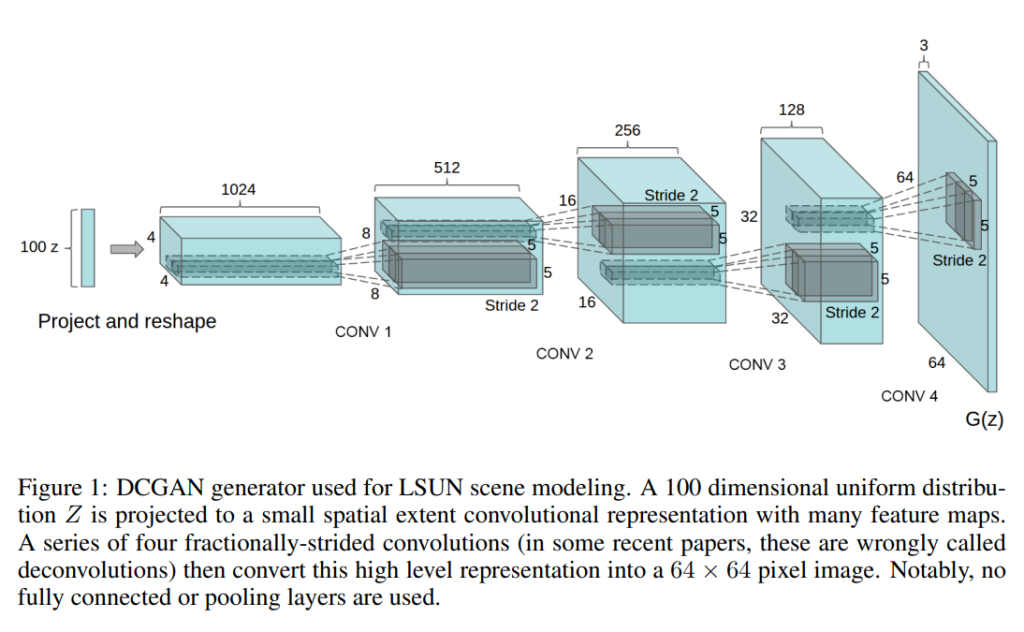
4.1 LSUN
”LSUN”は、Large-scale Scene Understanding Challengeという画像認識のコンペティションで使用されるデータセットです。このデータセットには、ベッドルーム、居間、キッチン、ダイニングルーム、バスルームなどの部屋の画像が含まれています。LSUNデータセットは、約300万枚のトレーニング画像を含んでおり、高品質な画像生成モデルをトレーニングするために使用されます。 本論文では、LSUNデータセットを使用してDCGANsをトレーニングする方法について詳しく説明されています。また、トレーニング中に発生する問題やその解決策についても言及されており、「No data augmentation was applied to the images.」という記述があります。これは、画像拡張技術を使用せずに元の画像だけを使用してDCGANsをトレーニングしたことを意味しています。 LSUNデータセットは、一般的な画像認識や生成モデルのトレーニングに広く使用されており、高品質な画像生成モデルの開発に貢献しています。
4.1.1 DEDUPLICATION
”DEDUPLICATION”は、Deep Convolutional Generative Adversarial Networks(DCGANs)のトレーニング中に使用される画像データの重複排除技術です。本論文では、3072-128-3072 de-noising dropout regularized RELU autoencoderを使用して32×32のトレーニング画像を処理し、その結果得られたコード層アクティベーションをバイナリ化することで、画像データの重複排除を行っています。 具体的には、まず32×32のトレーニング画像から中央部分を切り出し、3072次元のベクトルとして表現します。次に、de-noising dropout regularized RELU autoencoderを使用してこのベクトルを128次元に圧縮し、再び3072次元に復元します。この過程で得られたコード層アクティベーションは、ReLUアクティベーションの閾値化によってバイナリ化されます。このバイナリ化されたコード層アクティベーションは、線形時間で重複排除が可能なセマンティック・ハッシュとして機能し、高い精度で重複画像を検出することができます。 本論文では、「Visual inspection of hash collisions showed high precision with an estimated false positive rate of less than 1 in 100.」という記述があります。これは、ハッシュの衝突を視覚的に検査した結果、偽陽性率が100枚中1枚以下である高い精度が得られたことを示しています。
4.2 FACES
”4.2 FACES”は、Deep Convolutional Generative Adversarial Networks(DCGANs)のトレーニングに使用される人物画像データセットについて説明した節です。このデータセットは、人物の顔画像を含むものであり、dbpediaから取得した現代生まれの10,000人の名前をクエリとしてランダムなWeb画像からスクレイピングされました。このデータセットには約300万枚の画像が含まれており、OpenCVフェイス検出器を使用して顔領域を抽出し、約35万個の顔ボックスが得られました。 本論文では、「We use these face boxes for training. No data augmentation was applied to the images.」という記述があります。これは、元の画像だけを使用してDCGANsをトレーニングし、画像拡張技術は使用しなかったことを意味しています。 このような人物画像データセットは、一般的な画像認識や生成モデルのトレーニングに広く使用されており、高品質な顔画像生成モデルの開発に貢献しています。
4.3 IMAGENET-1K
”IMAGENET-1K”は、Deep Convolutional Generative Adversarial Networks(DCGANs)のトレーニングに使用される画像データセットの一つであり、自然画像を含むものです。このデータセットは、ImageNet Large Scale Visual Recognition Challenge(ILSVRC)の一部として作成されました。ILSVRCは、大規模な画像認識コンペティションであり、2010年から毎年開催されています。 IMAGENET-1Kには、1000種類の異なるオブジェクトカテゴリーに属する約120万枚の画像が含まれています。これらの画像は、高解像度で撮影されたものであり、多様な背景や照明条件で撮影されたものが含まれています。 本論文では、「We use Imagenet-1k (Deng et al., 2009) as a source of natural images for unsupervised training. We train on 32 × 32 min-resized center crops. No data augmentation was applied to the images.」という記述があります。これは、32×32ピクセルにリサイズした中央部分を切り出した画像を使用してDCGANsをトレーニングし、元の画像だけを使用していることを意味しています。 IMAGENET-1Kは、一般的な画像認識や生成モデルのトレーニングに広く使用されており、高品質な画像生成モデルの開発に貢献しています。
5.EMPIRICAL VALIDATION OF DCGANS CAPABILITIES
5.1 CLASSIFYING CIFAR-10 USING GANS AS A FEATURE EXTRACTOR
本セクションは、Deep Convolutional Generative Adversarial Networks(DCGANs)のトレーニングに使用される画像データセットであるCIFAR-10を分類するために、GANsを特徴抽出器として使用する方法について説明した節です。 CIFAR-10は、32×32ピクセルのカラー画像からなるデータセットであり、10種類の異なるオブジェクトカテゴリーに属する約6万枚の画像が含まれています。本論文では、CIFAR-10データセットを使用してDCGANsをトレーニングし、その後、トレーニング済みのDCGANsを特徴抽出器として使用して線形モデルをトレーニングしました。 具体的には、DCGANsの生成器部分を使用してCIFAR-10データセットから新しい画像を生成し、その生成された画像から特徴マップを抽出します。これらの特徴マップは、線形モデルの入力として使用されます。このようにして得られた線形モデルは、CIFAR-10データセットで80.6%という高い精度で分類タスクを実行することができました。 このようなGANsを特徴抽出器として使用する手法は、一般的な画像認識や生成モデルのトレーニングに広く使用されており、高品質な画像生成モデルの開発に貢献しています。
5.2 CLASSIFYING SVHN DIGITS USING GANS AS A FEATURE EXTRACTOR
本セクションは、Deep Convolutional Generative Adversarial Networks(DCGANs)のトレーニングに使用される画像データセットであるSVHN(Street View House Numbers)を分類するために、GANsを特徴抽出器として使用する方法について説明した節です。 SVHNは、Googleが公開した10種類の数字(0〜9)が含まれる32×32ピクセルのカラー画像からなるデータセットであり、約73,257枚のトレーニング画像と26,032枚のテスト画像が含まれています。本論文では、SVHNデータセットを使用してDCGANsをトレーニングし、その後、トレーニング済みのDCGANsを特徴抽出器として使用して線形モデルをトレーニングしました。 具体的には、DCGANsの識別器部分を使用してSVHNデータセットから新しい画像から特徴マップを抽出します。これらの特徴マップは、線形モデルの入力として使用されます。このようにして得られた線形モデルは、SVHNデータセットで82.8%という高い精度で分類タスクを実行することができました。 このようなGANsを特徴抽出器として使用する手法は、一般的な画像認識や生成モデルのトレーニングに広く使用されており、高品質な画像生成モデルの開発に貢献しています。
6. INVESTIGATING AND VISUALIZING THE INTERNALS OF THE NETWORKS
本セクションは、Deep Convolutional Generative Adversarial Networks(DCGANs)の内部を調査し、可視化する方法について説明した節です。 本論文では、トレーニングされたDCGANsの生成器と識別器を様々な方法で調査しています。具体的には、トレーニングセット内の最近傍探索は行っていません。ピクセル空間や特徴空間での最近傍探索は行われていません。 代わりに、本論文では、生成器と識別器の内部表現を可視化するために、畳み込み層のフィルターを表示し、各層で抽出された特徴マップを表示しています。また、生成器がどのように学習したかを理解するために、ランダムなノイズベクトルから生成された画像を可視化しています。 これらの手法により、DCGANsがどのように画像を生成し、どのような特徴を抽出するかを理解することができます。このような内部表現の可視化は、一般的な画像認識や生成モデルのトレーニングに広く使用されており、高品質な画像生成モデルの開発に貢献しています。
6.1 WALKING IN THE LATENT SPACE
本セクションは、Deep Convolutional Generative Adversarial Networks(DCGANs)のトレーニングに使用される潜在空間(latent space)を歩くことで、モデルが学習した表現を理解する方法について説明した節です。 本論文では、学習された潜在空間上を歩くことで、モデルがどのような表現を学習したかを理解しようとしています。具体的には、学習された多様体上を歩くことで、モデルが記憶しているかどうか(急激な遷移がある場合)、空間が階層的に折り畳まれているかどうかなどを理解しようとしています。また、この潜在空間上で歩くことで、画像生成に意味的な変化が生じるかどうか(例えば、オブジェクトの追加や削除)を確認することもできます。 本論文では、この手法によって得られた結果を図4に示しています。これらの結果からは、DCGANsが画像生成に必要な有用な表現を学習していることが示唆されます。このような潜在空間の理解は、一般的な画像認識や生成モデルのトレーニングに広く使用されており、高品質な画像生成モデルの開発に貢献しています。
6.2 VISUALIZING THE DISCRIMINATOR FEATURES
本セクションは、Deep Convolutional Generative Adversarial Networks(DCGANs)のトレーニングに使用される識別器が学習した特徴を可視化する方法について説明した節です。 本論文では、DCGANsの識別器が学習した特徴を可視化するために、過去の研究で提案された手法であるguided backpropagationを使用しています。具体的には、識別器が典型的なベッドルームの部分(ベッドや窓など)に反応するような特徴を学習しています。 このような特徴の可視化は、DCGANsがどのような表現を学習し、画像生成や画像認識タスクにどのように役立つかを理解する上で重要です。また、この手法は一般的な画像認識や生成モデルのトレーニングに広く使用されており、高品質な画像生成モデルの開発に貢献しています。
6.3 MANIPULATING THE GENERATOR REPRESENTATION
6.3.1 FORGETTING TO DRAW CERTAIN OBJECTS
本セクションは、Deep Convolutional Generative Adversarial Networks(DCGANs)のトレーニングに使用される生成器が学習した特定のオブジェクト表現を削除することで、その表現が画像生成にどのように影響するかを調べる方法について説明した節です。 本論文では、ベッド、窓、ランプ、ドアなどの主要なシーンコンポーネントのための特定のオブジェクト表現を学習していることが示唆されています。このような表現がどのように機能するかを理解するために、本論文では、生成器から窓を完全に削除する実験を行っています。 結果として得られた画像は、窓が存在しない場合でも十分な品質であったことから、生成器が他のオブジェクト表現を使用して画像を生成できることが示されました。このような実験は、DCGANsがどのような表現を学習し、画像生成や画像認識タスクにどのように役立つかを理解する上で重要です。
6.3.2 VECTOR ARITHMETIC ON FACE SAMPLES
本セクションは、Deep Convolutional Generative Adversarial Networks(DCGANs)のトレーニングに使用される生成器が学習した表現空間で、単純なベクトル演算を行うことで、意味的に関連する画像を生成する方法について説明した節です。 本論文では、単語の表現を評価する文脈で、Mikolovら(2013)は、単純な算術演算が表現空間内の豊富な線形構造を明らかにすることを示しました。例えば、「王」のベクトルから「男性」のベクトルを引き、「女性」のベクトルを加えると、「女王」のベクトルが最も近い隣接点となることが示されました。本論文では、このような構造が生成器の表現空間でも生じるかどうかを調べています。 具体的には、視覚的概念の例示サンプルセットのZベクトル上で同様の演算を行っています。1つだけのサンプルで実験すると不安定であったため、3つのサンプルからZベクトルを平均化することで、意味的に関連する画像を安定して生成することができました。 このようなベクトル演算は、DCGANsがどのような表現を学習し、画像生成や画像認識タスクにどのように役立つかを理解する上で重要です。また、この手法は一般的な画像認識や生成モデルのトレーニングに広く使用されており、高品質な画像生成モデルの開発に貢献しています。本論文で示された結果からは、DCGANsが意味的に関連する画像を生成するための表現空間を学習していることが示唆されます。このような表現空間の理解は、一般的な画像認識や生成モデルのトレーニングに広く使用されており、高品質な画像生成モデルの開発に貢献しています。
7. CONCLUSION AND FUTURE WORK
本セクションでは、本論文の結論と今後の研究について述べています。 本論文では、Deep Convolutional Generative Adversarial Networks(DCGANs)を使用して、高品質な画像生成モデルをトレーニングする方法を提案しました。具体的には、安定したアーキテクチャを使用してDCGANsをトレーニングし、識別器が学習した特徴の可視化や生成器が学習した表現空間でのベクトル演算などの実験を行いました。 結果として得られた画像は、従来の手法よりも高品質であり、人間が生成した画像に近いものであることが示されました。また、DCGANsがどのような表現を学習し、画像生成や画像認識タスクにどのように役立つかを理解する上で重要な知見が得られました。 今後は、さらに高品質な画像生成モデルの開発や、DCGANsを用いた他のタスクへの応用などが期待されます。また、本論文で提案された手法や知見は一般的な画像認識や生成モデルのトレーニングにも応用できるため、今後の研究においても重要な役割を果たすことが期待されます。