On the security of machine learning in malware C&C detection: a survey
概要:
この論文は、マルウェアのC&Cサーバ検出における機械学習の適用についての論文を集めたメタ分析論文です。著者は、マルウェア攻撃に対する防御の難しさと、攻撃の成功に必要な個々のステップを検出して妨害することの重要性について説明しています。本論文の主眼は、侵害されたシステムがコントローラーと通信するために確立するC&Cチャネルを特定するためのアプローチや技術を体系的にまとめることですが、これらの検出技術は攻撃者による回避試行への耐性が不十分であることが多いといわれています。C&Cサーバの特定を機械学習で行うアプローチが難しい理由と、逆に機械学習アルゴリズムに対する攻撃が成功しやすい理由、および将来の展望について、本論文で触れています。
1.本論文における目的
1-1 マルウェアについて
マルウェア攻撃の一般的な構造について認識を合わせていきます。マルウェア攻撃は、ボットネットの形で無差別に行われる場合と、特定の個人や組織から機密データを入手し、持ち出すことを目的とした狙った攻撃である場合があります。攻撃ステップやその命名法は出版物によって異なる場合がありますが、一般的には図1に示されるステップのような手順のシーケンスとして表現されます。
1-2 本論文の焦点
本論文の焦点は、機械学習(ML:Machine Learning)を使用したC&Cサーバ特定における攻撃者の回避耐性(*)について、現状(2016年当時)の状況と、将来への研究課題について明らかにすることです。
*回避耐性:攻撃者が検出技術を回避するために使用できる手法やテクニックに対するシステムの耐性のことです。この本論文では、C&C検出システムの機械学習コンポーネントが攻撃者による回避試行に対してどの程度耐性があるかを分析しています。
2.一般的なC&Cサーバ検出アーキテクチャ
一般的なC&C検出システムのアーキテクチャは、既にトレーニングフェーズが完了してデプロイされたシステムが前提にあります。アーキテクチャには、ネットワークトラフィックを収集するためのネットワークゲートウェイ、機械学習コンポーネント、ルールベースのコンポーネント、およびアラート生成と可視化のためのインタフェースが含まれます。図2に一般的なC&Cサーバ検出アーキテクチャを示します。
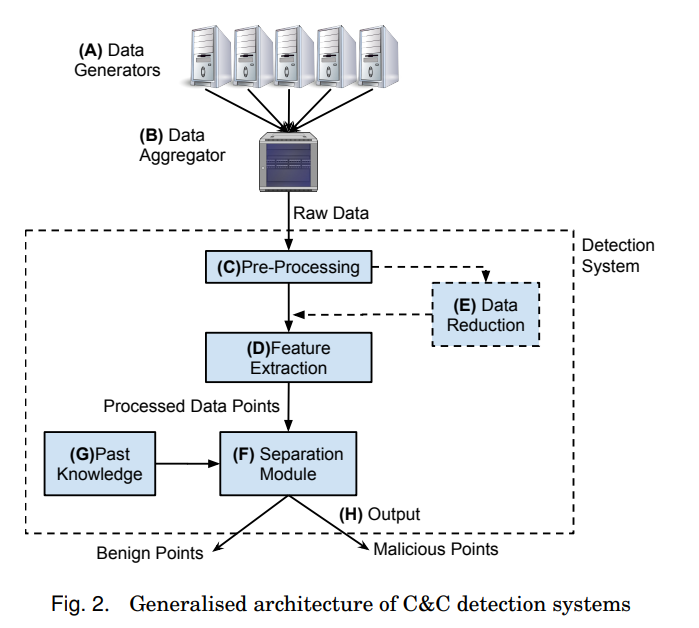
2.アーキテクチャ
一般的なアーキテクチャは、ネットワークトラフィックを収集するためのデータジェネレータ(A)、データを前処理するための前処理コンポーネント(B)、特徴抽出とデータ削減を行うための特徴抽出コンポーネント(C,D,E)、異常なトラフィックを検出するために使用される機械学習コンポーネント(F)、ルールベースのコンポーネントおよび過去の知識が含まれる過去知識コンポーネント(G)から構成されています。これらのコンポーネントは、異常なトラフィックを分離し、アラートや可視化データを生成するための出力コンポーネント(H)によって補完されます。
以下に一般的なC&Cサーバ検出アーキテクチャのコンポーネントを改めてまとめます。
1. データジェネレータ:ネットワークトラフィックを生成するデバイスやソフトウェアなどのコンポーネントです。
2. データアグリゲータ:データジェネレータから収集されたトラフィックを集約するコンポーネントです。
3. 前処理:データを正規化し、不要な情報を削除するためのコンポーネントです。
4. 特徴抽出:前処理されたデータから有用な特徴を抽出するためのコンポーネントです。
5. データ削減:特徴抽出されたデータを縮小するためのコンポーネントです。
6. 分離モジュール:正常なトラフィックと異常なトラフィックを分離するためのコンポーネントです。
7. 機械学習コンポーネント:異常なトラフィックを検出するために使用される機械学習アルゴリズムが含まれるコンポーネントです。
8. ルールベースのコンポーネント:機械学習コンポーネントによって検出されなかった異常なトラフィックを検出するためのルールベースのアルゴリズムが含まれるコンポーネントです。
9. 過去の知識:過去に収集された正常なトラフィックと異常なトラフィックの情報が含まれます。このコンポーネントは、機械学習コンポーネントが異常なトラフィックを検出するために使用されるトレーニングデータを提供します。
10. 出力:検出された異常なトラフィックの情報が含まれるアラートや可視化データを生成するためのコンポーネントです。
3.2016年現在のC&Cサーバ検出アプローチの評価
この章では、2016年現在のC&C検出アプローチについて包括的なレビューが提供されています。
3-1.C&Cサーバ検出アプローチの評価(レガシーなアプローチに対する評価)
①ネットワークフロー解析:ネットワークフロー解析は、ネットワーク上で発生する通信を分析し、異常なトラフィックを検出するために使用されます。このアプローチは、通信パターンを分析することでC&Cトラフィックを特定します。
②パケット解析:パケット解析は、ネットワーク上で送信されるパケットを分析し、異常なトラフィックを検出するために使用されます。このアプローチは、特定のパターンや署名を持つパケットを特定することでC&Cトラフィックを検出します。
③機械学習:機械学習は、異常なトラフィックを自動的に識別するために使用されます。このアプローチでは、正常なトラフィックと異常なトラフィックの両方を学習し、異常なトラフィックを検出するためのモデルを作成します。
④ ルールベース:ルールベースのアプローチは、特定のパターンや署名に基づいて異常なトラフィックを検出するために使用されます。このアプローチでは、事前に定義されたルールが使用されます。
①から④のアプローチは、異常なトラフィックを検出するために使用されますが、それぞれに利点と欠点があります。ネットワークフロー解析は、通信パターンを分析することでC&Cトラフィックを特定できますが、高度な暗号化技術に対しては有効ではありません。パケット解析は、特定のパターンや署名を持つパケットを特定することでC&Cトラフィックを検出しますが、新しい攻撃に対しては有効ではありません。機械学習は、異常なトラフィックを自動的に識別するために使用されますが、適切なトレーニングデータが必要であり、誤検知率が高い場合があります。ルールベースのアプローチは、事前に定義されたルールに基づいて異常なトラフィックを検出しますが、新しい攻撃に対しては有効ではありません。
C&Cサーバ検出の成功と誤検知の本論文での定義についてここでまとめます。C&C検出システムの成功を測定するための2つの主要な指標である真陽性率(TP)と偽陽性率(FP)について説明します。真陽性率は、悪意のあるサンプルが正しくマルウェアとしてラベル付けされた割合を測定し、偽陽性率は、正当なサンプルが誤ってマルウェアとしてラベル付けされた数を測定します。このセクションでは、C&C検出に関する他の評価指標も紹介されていますが、TPおよびFP率はC&C検出文献で最も一般的に提供されるため、比較目的でこれらを使用しています。
3-2.データの品質について
マルウェアC&Cを検出する際の、収集および分析するデータの選定が非常に重要です。異なる検出方法には、データの詳細度に異なるレベルが必要です。企業向けC&C検出技術の多くは、トラフィックをすべて保存することが必要であるため、ネットワークが拡大するにつれて保存することがますます困難になります。したがって、C&Cトラフィックトレースが記録されない場合、検出システムは動作しません。一部の技術では、サンプリング技術を開発してスケーラビリティの制限を克服しようとしていますが、回避耐性要件を考慮せずに行われているため問題があります。また、C&C回避に対応して測定を調整することに関してもほとんど注意が払われていません。
3-3.署名ベースの検出法
署名ベースのアプローチは、既知のマルウェアに対して非常に効果的であり、特定のパターンや署名を持つマルウェアを検出することができます。しかし、新しいバリアントや更新されたマルウェアを検出することは困難であり、データが静止しているという前提条件があるため、新しい攻撃に対しては有効ではありません。
署名ベースの検出方法の利点は、既知のマルウェアに対して非常に効果的であることです。特定のパターンや署名を持つマルウェアを検出することができます。また、この方法は比較的シンプルであり、実装が容易であるため、多くのセキュリティソフトウェアに採用されています。
一方、署名ベースの検出方法にはいくつかの欠点があります。新しいバリアントや更新されたマルウェアを検出することが困難であり、データが静止しているという前提条件があるため、新しい攻撃に対しては有効ではありません。また、この方法はマルウェアを特定するために使用されるパターンや署名を事前に知っている必要があるため、未知のマルウェアを検出することはできません。さらに、攻撃者は簡単に署名を変更することができるため、この方法は回避されやすくなっています。
署名ベースのC&Cサーバ検出アプローチには、“Communication pattern detection”や“DNS traffic analysis”などがあります。それぞれについて下記で触れます。
・Communication pattern detection:
マルウェアは通常、C&Cサーバと通信するために特定のプロトコルを使用します。この特徴に着目し、既知のマルウェアサンプルから署名を生成し、新しいトラフィックをこれらの署名と比較することで、C&Cトラフィックを検出する方法のことです。
・DNS traffic analysis:
多くのマルウェアは、中央集権型のC&C構造を使用するため、DNSを利用して通信します。この特徴に着目し、既知のマルウェアに関連するドメインを特定する検出メカニズムを提供する方法のことです。
3-4.分類器ベースの検出法
分類器ベース検出法は、過去のサンプルを使用して新しいサンプルにラベルを割り当てます。データセット内の各データポイントは、一連の特徴量で表され、各データポイントのラベルが既知であるため、これは教師あり学習の例です。この方法は、署名ベースの検出方法と比較して柔軟性があり、未知のマルウェアを検出することができます。しかし、この方法は多くのトレーニングデータを必要とし、実装が複雑であるため、実際に使用する前に多くの時間とリソースを費やす必要があります。
3-5. クラスタリングベースの検出法
この方法は、マルウェアのトラフィックをクラスタリングし、異常なトラフィックを検出することによってC&Cサーバを検出します。既知のマルウェアサンプルから特徴量を抽出し、これらの特徴量を使用してマルウェアトラフィックをクラスタリングする方法について下記で触れます。この方法は、未知のマルウェアに対して非常に効果的であり、新しいバリアントや更新されたマルウェアを検出することができます。ただし、多くのトレーニングデータを必要とし、実装が複雑であるため、実際に使用する前に多くの時間とリソースを費やす必要があります。
3-5-1. DNSトラフィック分析に基づく検出方法
この方法は、DNSトラフィックを監視し、マルウェアに関連するドメインを特定することによってC&Cサーバを検出します。具体的には、まずNotosと呼ばれるシステムによってドメイン名の評判を使用して、悪意のある活動に関連するドメインを特定します。次にNotosは、IPアドレスとドメイン名の構文的類似性に基づいてドメインをクラスタリングし、k-meansクラスタリングアルゴリズムを使用します。DNSトラフィック分析は、既知のマルウェアに対して非常に効果的であり、特定のドメインやパターンを持つマルウェアを検出することができます。ただし、新しいバリアントや更新されたマルウェアを検出することは困難であり、データが静止しているという前提条件があるため、新しい攻撃に対しては有効ではありません。
3-5-2. Fast Flux Network(FFSN)での検出方法
FFSNは、多数の侵害されたホストのプロキシーの背後にC&Cサーバが隠れているネットワークです。このタイプのC&Cサーバの検出は比較的容易に検出できます。DNSクエリを実行すると、サーバのドメインから大量かつ常に変化するIPアドレスが返されます。この特徴を持つサーバこそがC&Cサーバであるのです。
3-6. ハイブリッド検出システムを活用した検出方法
この方法は、複数の検出方法を組み合わせることによって動作します。例えば、BotMinerと呼ばれるシステムは、特定のボットネットに関する事前知識がなくても感染したホストを検出することができます。このシステムでは、Snort IDS用のカスタム署名を使用して活動を監視し、類似した通信パターンを持つホストをクラスタリングしてボットを特定します。つまり、DNSトラフィック分析やクラスタリングなどの他の検出方法と組み合わせることで、より効果的な検出が可能である、ということです。
3-7. グラフベースの検出法
この方法は、マルウェアの動作をグラフとして表現し、異常なパターンを検出することによってC&Cサーバを検出します。グラフベースの検出方法に関する研究が多数、既存の手法が確立されています。例えば、マルウェアのAPI呼び出しをグラフとして表現し、異常なパターンを検出する方法があります。また、マルウェアのファイルシステム操作やレジストリ操作をグラフとして表現することもできます。これらの手法は、既知のマルウェアに対して非常に効果的であり、新しいバリアントや更新されたマルウェアを検出することができます。ただし、多くのトレーニングデータを必要とし、実装が複雑であるため、実際に使用する前に多くの時間とリソースを費やす必要があります。
4.機械学習に対する回避耐性について
4-1.機械学習(ML)アルゴリズムの弱点
近年、洗練されたターゲット型マルウェア攻撃が増加しており、MLを用いてもC&Cサーバの特徴検出が回避されてしまうことが増加傾向にあります。このセクションでは、MLアルゴリズムが敵対的な攻撃に対して脆弱であることが指摘されており、これらの攻撃に対処するためにはより高度な防御手法が必要であることが示唆されています。言い換えれば、MLの回避耐性(*)を上げることが必要である、ということです。
*回避耐性:攻撃者が検出技術を回避するために使用できる手法やテクニックに対するシステムの耐性のことです。この本論文では、C&C検出システムの機械学習コンポーネントが攻撃者による回避試行に対してどの程度耐性があるかを分析しています。
機械学習アルゴリズムに対する攻撃を分類する3つの基本的脅威モデルは、攻撃者がどのようにして攻撃を行うかに基づいて、次の3つのカテゴリに分類されます。
1. White-box attacks: 攻撃者がアルゴリズムの内部構造やパラメータを知っている場合に発生します。
2. Black-box attacks: 攻撃者がアルゴリズムの内部構造やパラメータを知らない場合に発生します。
3. Gray-box attacks: 攻撃者がアルゴリズムの一部だけを知っている場合に発生します。
このカテゴリは、MLアルゴリズムに対する攻撃手法を分類するためだけでなく、防御策を開発するための指針としても使用できます。
4-2.機械学習アルゴリズムへの攻撃の目的について
マルウェア攻撃者の目的は大きく分けて次の2つです。
① 匿名性を実現すること:攻撃者は自分たちの存在を隠すことを目的としています。
② 検出技術の完全性を破壊すること:攻撃者は検出技術の正確性や信頼性を低下させることを目的としています。
上記の目的を達成するための攻撃者がターゲットシステムに対して持つ知識のレベルについて触れます。PDFRate(*)システムに対する攻撃を例に挙げ、攻撃者に必要な知識を以下の3つに分類します。
1. クラス分類器(およびそのパラメータ)に関する知識
2. 使用される特徴セットに関する知識
3. トレーニングセットに関する知識
これらの知識を組み合わせることで、攻撃者はより効果的な攻撃を行うことができます。逆に言えば、上記の3つの知識を攻撃者に与えないように、こちらが持つカード(トレーニングセットに関する情報、使用される特徴セットに関する情報)を伏せて、攻撃者からはわからないようにすることが、機械学習アルゴリズムでのC&Cサーバ検出において重要になる、ということです。
上記の2.と3.が攻撃者から見てわからない場合、攻撃者は入力(トレーニングまたはテスト)データを変更する以外の選択肢がなくなります。それに対して、こちらはデータの改ざんの対策をすれば、攻撃者の機械学習を用いたC&Cサーバ検出の妨害ができなくなり、C&Cサーバの特定につなげることができます。
<機械学習アルゴリズムへの攻撃に関する議論のために必要な用語>
1. Learner:機械学習アルゴリズムを指します。
2. Surrogate learner:攻撃者がテスト攻撃を行うために作成したLearnerのコピーです。Surrogate learner
は、攻撃者の知識レベルに応じて異なる完全性を持ちます。
3. Production learner:ターゲットが使用しているLearnerのインスタンスです。
これらの用語は、攻撃者がマルウェア防御システムを攻撃する際に使用されます。
5.機械学習のアルゴリズムに対する攻撃のサーベイ
マルウェアC&C検出システムに使用される機械学習アルゴリズムに対する攻撃について本章で触れます。このセクションでは、攻撃の目的(*回避または毒化)と、影響を受けるアルゴリズムのグループ(分類器またはクラスタリング)に基づいて攻撃をグループ化しています。さらに、それぞれの攻撃技術について説明し、文献から実証された攻撃の例を示し、攻撃の制限についても議論しています。このセクションでは、4節で定義されたモデルに従って攻撃が分類されます。次の章の6節では、これらの攻撃がC&C検出問題に与える影響についても議論しています。また、現在のマルウェアが検出を回避するために使用する既存のホストベース技術も説明しています。
*回避攻撃:トレーニングデータやテストデータを改ざんすることで検出率を低下させる攻撃
毒化攻撃:トレーニングデータやテストデータに偽情報を混入させることで誤った結果を導き出す攻撃
5-1.回避攻撃-分類器
5-1-1. Mimicry attack
回避攻撃の一種であり、攻撃者がトレーニングデータやテストデータを改ざんすることで、検出率を低下させる手法の一つです。具体的には、悪意のあるポイントと良性のポイントの分布に関する知識を利用して、攻撃ポイントと良性ポイントの距離を効果的に縮小することで、機械学習アルゴリズムを攻撃する手法です。この攻撃は、ランダムフォレスト、ベイズ、SVM分類器に対して有効な攻撃であると実証されています。ランダムフォレストは複数の決定木ベースの分類器であるため、単一決定木ベースのアルゴリズムに対しても効果的な攻撃であると考えられます。また、勾配降下攻撃としての一面も示されており、これはSVMやニューラルネットワークなどの微分可能な識別関数を持つ任意の分類器に対して理論的に機能することが示されています。
5-1-2. Gradient descent attacks
「Gradient descent attacks」は、機械学習アルゴリズムを攻撃する手法の1つであり、分類器やクラスタリングアルゴリズムに適用されます。この攻撃では、勾配降下関数を適用して、望ましい結果(ポイントの誤分類)を達成するための攻撃ポイントの状態を見つけるために、勾配降下アルゴリズムが反復的に使用されます。勾配降下は最適化アルゴリズムであり、関数の勾配の負方向に点(パラメータ値を変更して)を反復的に移動することで関数を最小化することを目的とします。回避攻撃の場合、これらは探索的な整合性攻撃の例の一つです。典型的なアプローチは、攻撃ポイントを生成し、代替学習者でその有効性をテストすることです。「Gradient descent attacks」は、「Mimicry attack」と同様に敵対的な攻撃手法です。
5-1-3. Other attacks.
これまでで触れた以外の機械学習のアルゴリズムに対する攻撃は、ランダムサンプリング、クラスタリング、特徴量選択などの手法を使用して実行されます。例えば、「ランダムサンプリング」攻撃では、攻撃者はランダムにデータポイントを選択し、それらを教師データセットに追加することで分類器を混乱させます。「クラスタリング」攻撃では、攻撃者は教師データセット内のクラスターを変更することで分類器を混乱させます。「特徴量選択」攻撃では、攻撃者は教師データセットから特定の特徴量を削除することで分類器を混乱させます。これらの攻撃は、「Gradient descent attacks」と「Mimicry attack」と同様に敵対的な手法です。
5-2 毒化攻撃 – 分類器
5-2-1. Label Flipping attacks
この攻撃は、教師データセット内のラベルを反転させることによって実行されます。攻撃者は、正当なサンプルを悪意のあるものとしてラベル付けしたり、悪意のあるサンプルを正当なものとしてラベル付けしたりすることができます。これにより、分類器が誤った予測を行う可能性があります。この攻撃は最も一般的な攻撃手法です。しかし、予算制限や攻撃者の知識不足などによって攻撃の効果が制限される場合があります。
5-2-2. Dictionary attacks
この攻撃は、トークンベースの特徴を使用してトレーニングされた分類器に対して実行されます。攻撃者は、良性データに含まれるトークン(例えば単語)を含む悪意のあるデータをトレーニングセットに挿入します。目的は、悪意のあるデータが発見され、将来のトレーニングセットに含まれるようにすることです。その後、良性データが誤って悪意のあるものとして分類されることで、原因不明な可用性攻撃が発生します。これは無差別(任意の良性ポイントが誤って分類される可能性がある)またはターゲット指向(特定の良性サンプルを誤って分類することを目的とする)攻撃である場合があります。
5-2-3. clustering
この攻撃は、敵対的なポイントをクラスタリングアルゴリズムに挿入することによって実行されます。攻撃者は、良性データに似た悪意のあるデータを生成し、それをクラスタリングアルゴリズムに挿入します。目的は、クラスターの分割やマージを引き起こすことです。階層的クラスタリングでは、クラスター間にポイントを挿入すると、クラスター間距離が影響を受けるため、クラスターがマージされる可能性があります。
5-2-4. Other attacks
「6.5.1. Model inversion attacks」は、モデルの出力から入力を推測することによって実行されます。これは、モデルが公開されている場合に特に問題となります。また、「6.5.2. Membership inference attacks」は、モデルが特定のトレーニングサンプルを含んでいるかどうかを判断することによって実行されます。これらの攻撃手法は、敵対的な攻撃手法の一部です。
5-3. Emerging host-based evasion techniques
マルウェアによって使用されているホスト側の技術を指します。例えば Emerging host-based evasion techniquesでは、これらの技術について簡単に説明されています。これらの技術には、検出と分析システムを回避するための方法が含まれます。他の例には Anti-VM and anti-sandbox techniquesがあり、マルウェアが仮想マシンやサンドボックスで実行されていることを検出し、それに応じた動作を行う方法です。また、Anti-debugging techniquesは、マルウェアがデバッガーで実行されていることを検出し、それに応じた動作を行う方法です。これらの技術は、マルウェア作者が検出と分析から逃れるために使用されます。
6.Discussion
6.1. Why is secure machine learning not in use for C&C detection?
この章はセキュアな機械学習アルゴリズムがC&C検出に広く使用されていない理由についての議論をまとめたものです。「7. DISCUSSION」で説明されています。以下は、その要約です。 – 意識不足:セキュアな機械学習アルゴリズムに関する意識不足があります。セキュアなアルゴリズムが存在することを知らない人々は、単純なアルゴリズムの脆弱性すら知らない可能性があります。 – 計算コスト:セキュアな機械学習アルゴリズムは、計算コストが高く、実行時間が長くかかる場合があります。これは、大規模で複雑なデータセットを扱う場合に特に問題となります。 – パフォーマンス:一部のセキュアな機械学習アルゴリズムは、パフォーマンスが低下する可能性があります。これは、正確さや偽陽性率に影響を与える可能性があります。 – 研究の不足:セキュアな機械学習アルゴリズムに関する研究がまだ不十分であるため、実装が困難である場合があります。
6.2. Difficulty of applying attacks in C&C
C&Cに対する攻撃の適用が困難である理由について説明しています。他の機械学習アルゴリズムへの攻撃と比較して、C&Cに対する攻撃は困難であるとされています。これは、以下の理由が挙げられます。 – 特徴量の制限:C&Cチャネルでは、パケット内容(長さ、n-gramなど)やパケット数やサイズなどの特徴量を変更することが困難であるため、攻撃者が特徴量を変更することができる範囲が限られていることが原因です。 – ノイズ:C&Cチャネルでは、通信中に発生するノイズやエラーも考慮する必要があります。これらの要因は、攻撃者によって制御されないため、攻撃手法を適用することを困難にします。 – データセットの不足:敵対的な攻撃手法を開発するためには大量のデータセットが必要ですが、C&Cチャネルのデータセットは限られているため、攻撃手法を開発することが困難になります。
6-3 Effectiveness against full C&C detection systems
この章では、C&C検出システムに対する攻撃の効果について説明しています。C&C検出システムは、機械学習アルゴリズムだけでなく、データの前処理や後処理(ホワイトリスト/ブラックリスト、ノイズ低減、データサンプリングなど)も行います。また、クラスタリングアルゴリズムを使用してデータを分離し、その後シグネチャを作成することがあります。これらの処理により、攻撃者が敵対的な攻撃手法を適用することが困難になります。 ただし、この章で触れているのは、5章で議論された攻撃例は、テストサンプルが特徴量抽出のみを受けてから直接機械学習アルゴリズムに入力されるシナリオに焦点を絞っています。つまり、「5章で議論された攻撃例」は、実際のC&C検出システムに対する攻撃ではなく、単純化されたシナリオでの攻撃に焦点を当てています。したがって、本章では、実際のC&C検出システムに対する攻撃の効果についての詳細な情報は含まれていません。
6-4. Limitations of current detection approaches
本章では、C&C検出アプローチの限界について説明しています。具体的には、以下のような制限が存在します。 – 限られたデータセット:有用なデータセットを取得することは、マルウェア研究者にとってよく知られた問題です。法的要件のため、作成されたデータセットは一度作成されるとリリースできない場合があります。また、これらのデータは現実世界の状況を正確に反映していない場合があります。 – ファイルレスマルウェア:ファイルレスマルウェアは、ファイルシステムを使用せずにメモリ内で実行されるため、従来の検出方法では検出することが困難です。 – ホスト側の回避技術:ホスト側の回避技術は、検出システムを回避するために使用されます。これらの技術は、攻撃者が検出から逃れることを可能にします。 – ゼロデイ攻撃:ゼロデイ攻撃は、既知の脆弱性を利用しないため、従来の検出方法では検出することが困難です。 これらの理由により、C&C検出アプローチには限界があります。
6-5 Attack defences
本章では、C&C検出システムに対する攻撃を防ぐための防御策については以下のような防御策が存在します。 – データの前処理:データの前処理は、データをクリーニングし、ノイズを低減することで、機械学習アルゴリズムの精度を向上させます。
– 特徴量選択:特徴量選択は、重要な特徴量だけを選択し、不要な特徴量を削除することで、機械学習アルゴリズムのパフォーマンスを向上させます。
– アンサンブル学習:アンサンブル学習は、複数の異なる機械学習アルゴリズムを組み合わせることで、精度や汎化性能を向上させます。 – 敵対的なサンプルの除去:敵対的なサンプルは、攻撃者が意図的に作成したものであり、機械学習アルゴリズムの性能を低下させる可能性があります。これらのサンプルを除去することで、機械学習アルゴリズムの精度を向上させます。
– ホワイトリスト/ブラックリスト:ホワイトリスト/ブラックリストは、許可された/拒否されたアプリケーションやIPアドレスなどのリストです。これらのリストを使用することで、機械学習アルゴリズムが正しい判断を下すことができます。
– ノイズの追加:ノイズをデータに追加することで、攻撃者が敵対的な攻撃手法を適用することを困難にします。 – アンサンブル学習の強化:アンサンブル学習は、複数の異なる機械学習アルゴリズムを組み合わせることで、精度や汎化性能を向上させます。この手法は、攻撃者が単一の機械学習アルゴリズムに対して敵対的な攻撃手法を適用する場合に有効です。
6-6. Open challenges
本章ではC&C検出における現在の課題について、以下の2つの主要な課題が存在します。 – 敵対的な攻撃を考慮した機械学習技術のクリーンスレート設計:現在の多くのC&C検出システムは、敵対的な攻撃を考慮していません。そのため、既存の非敵対的な機械学習技術にレイヤーを追加するだけでは不十分であり、敵対的な攻撃を考慮した新しいクリーンスレート設計が必要です。 – 回避耐性サンプリング技術の開発:現在のサンプリング技術は、十分なリソースを持つ攻撃者によって回避される可能性があります。そのため、回避耐性サンプリング技術(例えば、C&C検出に応答するために測定を調整する技術)の開発が必要です。
7.Conclusion
本章でC&C検出における現在の状況と今後の展望についてまとめると以下のような結論が得られます。 – C&C検出に関する研究は、過去10年間で大きく進歩しました。しかし、依然として多くの課題が残っています。
– 現在のC&C検出システムは、敵対的な攻撃を考慮していないため、攻撃者によって回避される可能性があります。
– 現在のC&C検出システムは、トラフィック行動に焦点を当てています。しかし、これらの行動はボットネットの機能に固有ではないため、攻撃者はこれらの保護を容易に回避できます。
– 機械学習技術を使用したC&C検出システムは有望ですが、敵対的な攻撃を考慮した新しいクリーンスレート設計が必要です。
– 回避耐性サンプリング技術(例えば、C&C検出に応答するために測定を調整する技術)の開発が必要です。 – 今後の研究では、敵対的な攻撃に対する回避耐性、リアルタイム処理、大規模データセットの取得などに焦点を当てる必要があります。