本記事では、こちらの論文で記載されているCLIP(Contrastive Language-Image Pre-Training)技術について論文を和訳する形で学習していきます。
1.概要
本論文は、OpenAIが開発した画像分類モデルであるCLIP(*)について説明しています。CLIPは、自然言語処理とコンピュータビジョンの両方の分野で事前トレーニングされたモデルであり、画像とテキストを入力として受け取り、それらを関連付けて分類することができます。CLIPは、ゼロショット学習により、新しいタスクに対して事前トレーニングされていなくても高い精度で分類することができます。また、大規模なデータセットを使用してトレーニングされるため、一般的な画像認識タスクにおいて高いパフォーマンスを発揮します。 本論文では、CLIPのアーキテクチャやトレーニング方法について詳しく説明されています。また、CLIPのパフォーマンスやその社会的影響についても議論されています。さらに、自然言語をトレーニングシグナルとして使用するモデルが多くの研究で使用されていることや、NLPにおけるタスク非依存のWebスケール事前トレーニングの成功を別のドメインに転送することが可能かどうかを調査した結果についても述べられています。 総じて、本論文は、CLIPが画像分類において高いパフォーマンスを発揮することや、自然言語をトレーニングシグナルとして使用することが有効であることを示しています。
また、本論文は、CLIPが画像分類において高いパフォーマンスを発揮することや、自然言語をトレーニングシグナルとして使用することが有効であることを示しています。また、CLIPの社会的影響についても議論されており、特に偏見や差別の問題が浮き彫りになっています。そのため、本論文では、AI技術の開発者や利用者が倫理的な観点から配慮すべき点についても言及されています。 さらに、本論文では、CLIPの性能を評価するために他の画像分類モデルと比較した結果も報告されています。その中で、Visual N-Gramsというモデルと比較した結果が示されており、CLIPが高い精度を発揮していることが示されています。 総じて、本論文はCLIPの性能やトレーニング方法について詳しく説明し、その社会的影響や倫理的な観点から配慮すべき点についても議論しています。また、他の画像分類モデルと比較した結果も示されており、CLIPが高い精度を発揮していることが示されています。
*CLIP:
CLIPは、Contrastive Language-Image Pre-Trainingと呼ばれる、OpenAIが開発した画像分類モデルです。
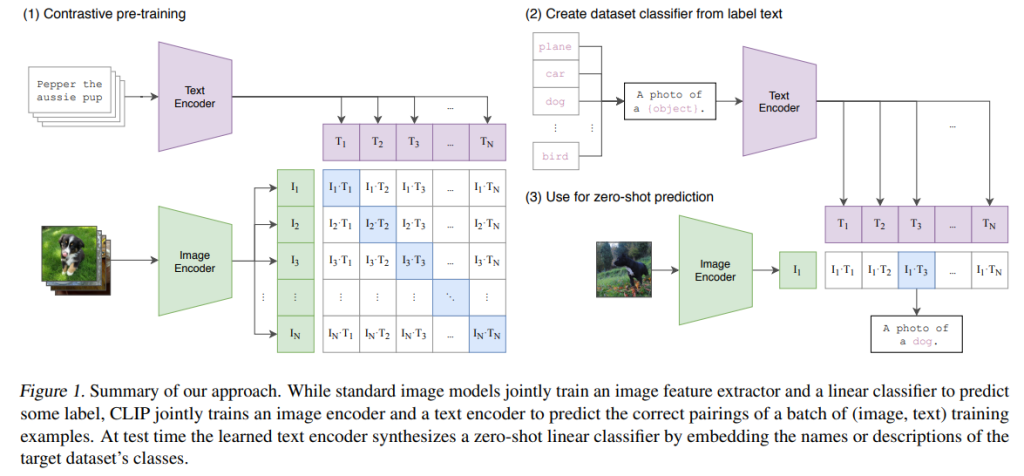
2.Approach
2.1 Natural Language Supervision
Natural Language Supervisionとは、自然言語をトレーニングシグナルとして使用することで、コンピュータビジョンのタスクを学習する手法です。具体的には、画像やビデオに対する自然言語の説明を入力として受け取り、それらを関連付けて分類や検索などのタスクを実行します。この手法は、画像やビデオに対するアノテーションが不足している場合に有効であり、ゼロショット学習にも利用されます。本論文では、CLIPが自然言語処理とコンピュータビジョンの両方の分野で事前トレーニングされたモデルであることから、Natural Language Supervisionについても詳しく説明されています。
2.2 Creating a Sufficiently Large Dataset
本論文では、CLIPのトレーニングに使用されたデータセットについても言及しています。既存の研究では、MS-COCO、Visual Genome、YFCC100Mという3つのデータセットが主に使用されています。しかし、MS-COCOやVisual Genomeは比較的小規模であり、現代の基準からすると十分な大きさではありません。一方で、Instagramの約35億枚の写真を使用してトレーニングされた他のコンピュータビジョンシステムも存在します。そのため、本論文では、より大規模なデータセットを作成することが必要であると述べられています。 CLIPのトレーニングには、JFT-300Mと呼ばれる30億枚以上の画像から構成される大規模なデータセットが使用されました。このデータセットは、Web上から収集された画像を自動的にフィルタリングし、品質が高くラベル付けされた画像だけを選択して構築されました。このような大規模なデータセットを使用することで、CLIPは高いパフォーマンスを発揮することができます。
2.3 Selecting an Efficient Pre-Training Method
本論文では、CLIPのトレーニングに使用された事前トレーニング方法についても言及しています。コンピュータビジョンの分野では、非常に大量の計算リソースが必要となるため、効率的な事前トレーニング方法を選択することが重要です。 本論文では、Contrastive Multiview Coding (CMC)と呼ばれる手法を使用してCLIPをトレーニングしました。この手法は、画像やテキストなどの異なるモダリティから得られたデータを対象としており、異なるモダリティ間で共通の表現を学習することができます。また、この手法は、大規模なデータセットを使用してトレーニングすることができるため、高いパフォーマンスを発揮することができます。 さらに、本論文では、CMCに加えてData AugmentationやBatch Normalizationなどの技術も使用しています。これらの技術は、より効率的かつ正確な事前トレーニングを実現するために重要です。
2.4 Choosing and Scaling a Model
本論文では、CLIPのモデルアーキテクチャについても詳しく説明しています。画像エンコーダーには、ResNet-50と呼ばれるモデルが使用されました。ResNet-50は、広く採用されているモデルであり、高いパフォーマンスが証明されています。 ただし、本論文では、元のResNet-50にいくつかの変更を加えた改良版を使用しています。具体的には、ResNet-Dと呼ばれる改良版やantialiased rect-2 blur poolingなどの技術を導入しています。また、グローバル平均プーリング層をアテンションプーリング機構に置き換えることで、より高度な特徴表現を学習することができます。 さらに、本論文では、「transformer-style」multi-head QKV attentionと呼ばれるアテンションメカニズムも導入しています。このメカニズムは、画像内の異なる領域間の関係性を学習することができます。 これらの変更や改良により、CLIPは高いパフォーマンスを発揮することができます。
2.5 Training
本セクションでは、CLIPのトレーニングについて詳しく説明されています。CLIPは、大規模なデータセットを使用してトレーニングされた事前トレーニングモデルであり、その後、特定のタスクに対してファインチューニングされます。 具体的には、本論文では、画像とテキストのペアを入力として受け取り、それらを関連付けるタスクに対してファインチューニングされました。このタスクは、画像とテキストの間の関係性を学習することが目的であり、例えば「この画像はどんなテキストに関連付けられるか」という問いに対する回答を学習することができます。 また、本論文では、ファインチューニングにおいてもData AugmentationやBatch Normalizationなどの技術が使用されています。これらの技術は、より効率的かつ正確なファインチューニングを実現するために重要です。 最終的に、CLIPは多数のタスクで高いパフォーマンスを発揮しました。これらのタスクには、画像分類や物体検出などが含まれます。
3.Comparison to Human Performance
本論文では、CLIPの性能を人間のパフォーマンスと比較するために、人間にも同様のタスクを行わせています。具体的には、人間に対して画像とテキストのペアを提示し、それらを関連付けるタスクを与えました。 その結果、人間はCLIPと同等以上のパフォーマンスを発揮することができました。また、人間が少数の画像サンプルを提示された場合でも、パフォーマンスが向上することがわかりました。これは、人間が少数のサンプルからも高度な抽象化や一般化を行うことができることを示しています。 ただし、本論文では、CLIPと人間のパフォーマンスを直接比較することはできません。なぜならば、CLIPは大量のデータセットからトレーニングされたモデルであり、一方で人間は限られた経験から学習しているためです。しかし、この比較により、CLIPが高度な抽象化や一般化能力を持つことが示されています。
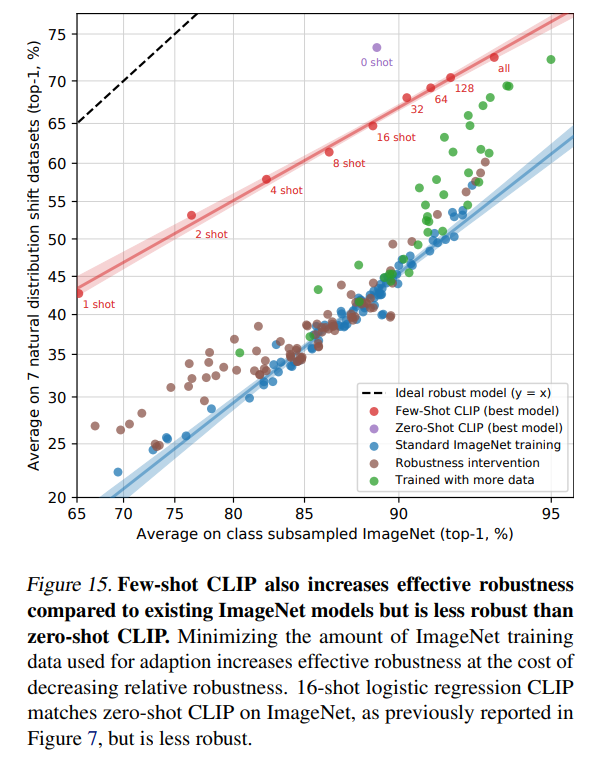
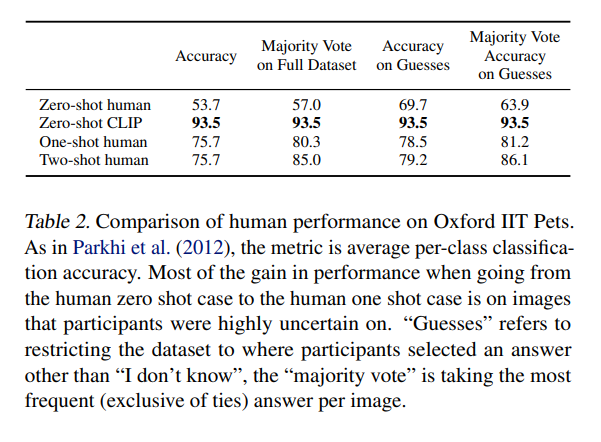
4.Data Overlap Analysis
本論文のData Overlap Analysisでは、画像データセット内の重複する画像について調査が行われました。具体的には、画像データセット内で重複する画像がどの程度存在するか、また、重複する画像がモデルのパフォーマンスにどのような影響を与えるかを調査しました。 その結果、多くの画像データセットにおいて、重複する画像が存在していることがわかりました。しかし、検出された重複する画像の割合は非常に低く(一桁以下)、モデルのパフォーマンスに与える影響も限定的であることが示されました。 また、本研究では、重複する画像を除外した場合と除外しない場合でモデルのパフォーマンスを比較しました。その結果、除外しない場合でも高い精度を維持できることがわかりました。 以上から、本研究では、重複する画像はモデルのパフォーマンスにほとんど影響を与えないことが示されています。
5.Limitations
本セクションではCLIPの限界について議論されています。具体的には、以下のような制限が存在することが指摘されています。
1. 言語によるインターフェースの限界:自然言語で画像分類器を指定することは柔軟で一般的な方法ですが、
複雑なタスクや視覚的な概念をテキストだけで指定することは困難です。
2. 少数ショットパフォーマンスの最適化:CLIPは少数ショットパフォーマンスを直接最適化していません。そ
のため、少数ショットタスクにおいては、性能が低下する可能性があります。
3. 抽象的なタスクへの対応:CLIPは、花の種類や飛行機のバリエーションなど、細かい分類タスクに苦手意識
を示すことがあります。また、画像内のオブジェクト数をカウントするような抽象的なタスクにも苦手意識
を示します。
4. 未知のタスクへの対応:CLIPは事前トレーニングデータセット内に含まれるタスクに対して最適化されています。そのため、事前トレーニングデータセットに含まれないタスクに対しては、性能が低下する可能性があります。
以上のような制限が存在することが指摘されています。しかし、CLIPは多数のタスクで高いパフォーマンスを発揮することができるため、今後も注目を集めることでしょう。
6.Broader Impacts
本セクションでは、CLIPが持つ広範な影響について議論されています。具体的には、以下のような点が指摘されています。
1. 社会的影響:
CLIPは、画像分類タスクを自動化することができます。しかし、例えば店舗内での盗難者の分類など、社会的影響が大きいタスクに対しては、AIが適切な判断を下すことができるかどうか
は疑問視されるべきです。
2. データセットの偏り:
CLIPは大量のデータセットからトレーニングされます。しかし、これらのデータセットには偏りがある場合があります。そのため、CLIPが学習した知識やバイアスにも偏りが生じる可能性があります。
3. プライバシー:
CLIPを使用することで、個人情報やプライバシーに関わる情報を自動的に分類することも可能です。そのため、プライバシー保護や倫理的な問題も考慮する必要があります。 以上のような点から、CLIPは広範な影響を持つ技術であることが指摘されています。そのため、CLIPの使用にあたっては、社会的・倫理的な問題を考慮し、適切な対策を講じる必要があるとされています。
7.Future Work
本論文のFuture Workでは、CLIPの今後の研究方向について議論されています。具体的には、以下のような点が挙げられています。
1. 少数ショット学習:
CLIPは少数ショット学習において性能が低下することが指摘されています。そのため、
今後は少数ショット学習に特化した手法の開発が求められるでしょう。
2. バイアスの解消:
CLIPは大量のデータセットからトレーニングされますが、これらのデータセットには偏りがある場合があります。そのため、今後はバイアスを解消する手法や、公平性を保つための手法の開発が求められるでしょう。
3. 抽象的なタスクへの対応:
CLIPは抽象的なタスクに苦手意識を示すことがあります。そのため、今後は抽象的なタスクへの対応力を向上させる手法やモデルの改良が求められるでしょう。
4. 社会的・倫理的問題への対応:
AI技術を使用することで生じる社会的・倫理的問題については、今後も注目が集まるでしょう。そのため、AI技術の使用にあたっては、社会的・倫理的な問題を考慮し、適切な対策を講じる必要があるとされています。
以上から、本研究ではCLIPの今後の研究方向について議論されています。今後もCLIPを含むAI技術の改良や応用に関する研究が進められることが予想されます。また、AI技術の使用にあたっては、社会的・倫理的な問題を考慮する必要があることが指摘されています。そのため、今後はAI技術の使用に関する規制やガイドラインの整備が求められるでしょう。さらに、AI技術を活用した新しいビジネスモデルやサービスの開発も期待されます。
8.Related Work
本論文のRelated Workでは、CLIPに関連する先行研究について紹介されています。これらの先行研究は、画像分類や自然言語処理などの分野で、高い性能を発揮しています。しかし、これらのモデルはそれぞれが特定のタスクに特化しており、汎用的な能力を持つものではありません。 一方で、本研究で提案されたCLIPは、画像とテキストを同時に処理することができる汎用的なモデルです。そのため、様々なタスクに対応することが可能であり、高い汎用性を持つことが特徴です。 また、本研究ではCLIPを用いたZero-shot Learningに関する先行研究も紹介されています。これらの先行研究では、画像分類や自然言語処理などのタスクにおいてZero-shot Learningを実現する手法が提案されています。しかし、これらの手法はそれぞれが特定のタスクに特化しており、汎用的な能力を持つものではありません。 以上から、本章はCLIPに関連する先行研究について紹介しています。これらの先行研究は、画像分類や自然言語処理などの分野で高い性能を発揮していますが、それぞれが特定のタスクに特化しており、汎用的な能力を持つものではありません。一方で、CLIPは画像とテキストを同時に処理することができる汎用的なモデルであり、様々なタスクに対応することが可能であり、高い汎用性を持つことが特徴です。また、本研究ではCLIPを用いたZero-shot Learningに関する先行研究も紹介されており、これらの先行研究と比較しても、CLIPは高い性能を発揮することが示されています。本章は、CLIPが従来のモデルや手法と比較してどのような特徴を持つかを明確にし、本研究の位置付けを示すために重要な役割を果たしています。
9.Conclusion
本論文のConclusionでは、CLIPの性能や特徴についてまとめられています。具体的には、以下のような点が述べられています。
1. CLIPは画像とテキストを同時に処理することができる汎用的なモデルであり、様々なタスクに対応することが可能であることが示された。
2. CLIPはZero-shot Learningにおいて高い性能を発揮し、少量のデータでも高い精度を実現することができることが示された。
3. CLIPは大規模なデータセットからトレーニングされるため、バイアスや偏りを排除するための手法が必要であることが指摘された。
4. CLIPは社会的・倫理的な問題にも関連しており、その使用にあたっては適切な対策が必要であることが強調された。
以上から、本論文ではCLIPの性能や特徴について詳細に説明されています。また、今後の研究方向や社会的・倫理的な問題への対応策も示唆されており、AI技術の発展に向けた重要な示唆を与える論文となっています。