研究2:PGGANを用いたAIによる画像生成の体験
(DCGANの限界サイズ(64✕64ピクセル)を超えた風景画の学習結果を出力)
・背景と目的
・アプローチ手法
・原理
・可視化方法
・可視化結果
・考察
【原理】
PGGANにでの実装例は、アプローチ手法で述べたとおりです。
リンク先からご確認ください。
より詳細に学びたい方は、こちらのリンク先のPDFを参照ください。
以下は上記で触れた論文に基づいたPGGANの原理について論文を要約する形で解説いたします。
【概要】(再掲)
PGGANは、Progressive Growing of GANsの略で、生成的対抗ネットワークの新しいトレーニング手法です。この手法は、低解像度から始めて、段階的に新しいレイヤーを追加して、トレーニングが進むにつれてますます細かい詳細をモデル化することで、ジェネレーター(生成器)とディスクリミネーター(判別器)を進化させることを特徴としています。これにより、トレーニングを高速化し、画像の品質、安定性、バリエーションを向上させることができます。この手法により、1024×1024の画像を生成することも可能になります。
特徴量の学習は、ジェネレーター(G)とディスクリミネーター(D)の両方が4×4ピクセルの低い空間分解能から始めます。学習が進むにつれて、GとDに段階的にレイヤーを追加して、生成された画像の空間分解能を徐々に高めています。このプロセス中、すべての既存のレイヤーはトレーニング可能なままです。ここで、N×NはN×Nの空間分解能で動作する畳み込み層を指します。これにより、高解像度で安定した合成が可能になり、トレーニングも大幅に高速化されます。
図1は徐々にレイヤーを加えていき、学習をするイメージ図を示しています。
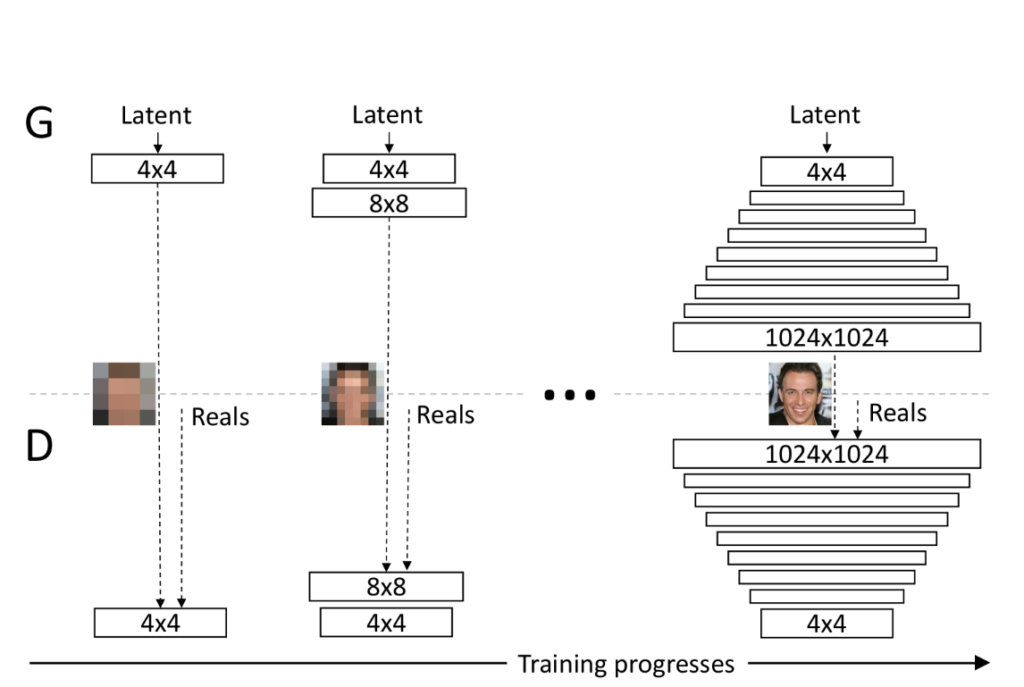
図1 PGGANの学習イメージ
下図はPGGANのアーキテクチャを示しています。左側には、ジェネレーター(G)のアーキテクチャが示されており、右側にはディスクリミネーター(D)のアーキテクチャが示されています。Gは、低解像度から高解像度へ段階的に成長するように設計されており、各成長段階で新しいレイヤーが追加されます。Dは、高解像度から低解像度へ段階的に成長するように設計されており、各成長段階で新しいレイヤーが追加されます。このアーキテクチャにより、高品質の画像を生成することができます。
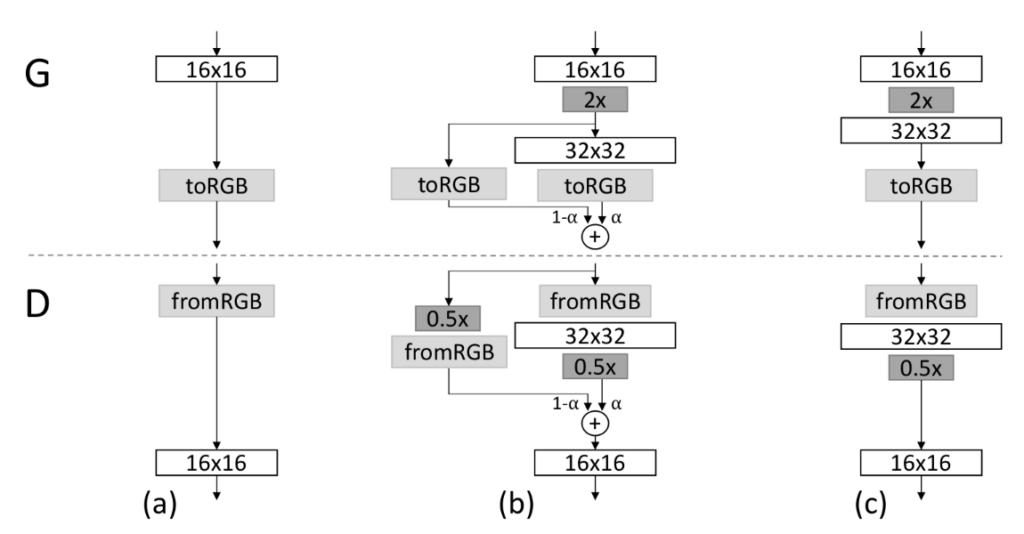
図2 PGGANのアーキテクチャ