研究1
「芸術(創造性)とAI(技術的描画)について」
・背景と目的
・アプローチ手法
・原理
・可視化方法
・可視化結果
・考察
【原理】
DCGANにおける原理は、アプローチ手法で述べたとおりです。
リンク先からご確認ください。
より詳細に学びたい方は、こちらのリンク先のPDFを参照ください。
以下は上記で触れた論文に基づいたDCGANの原理について論文を要約する形で解説いたします。
【概要】
DCGANとは、「deep convolutional generative adversarial network」の略称です。DCGANは、生成的対立ネットワークを用いた学習手法を採用しており、ジェネレータネットワークがランダムなノイズから現実的な画像を生成し、ディスクリミネータネットワークが本物の画像と生成された画像を区別することを学習します。この2つのネットワークは、競合的なプロセスで一緒に学習され、ジェネレータが本物の画像と区別できないような画像を生成するまで訓練されます。DCGANは、オブジェクトの部分からシーンまでの表現の階層を学習し、画像表現を超えた新しいタスクにも使用できることが示されています。これを図に示すと、図1のようになります。ここで、生成器とは”Generator”を指し、識別機は”discriminator”を指します。
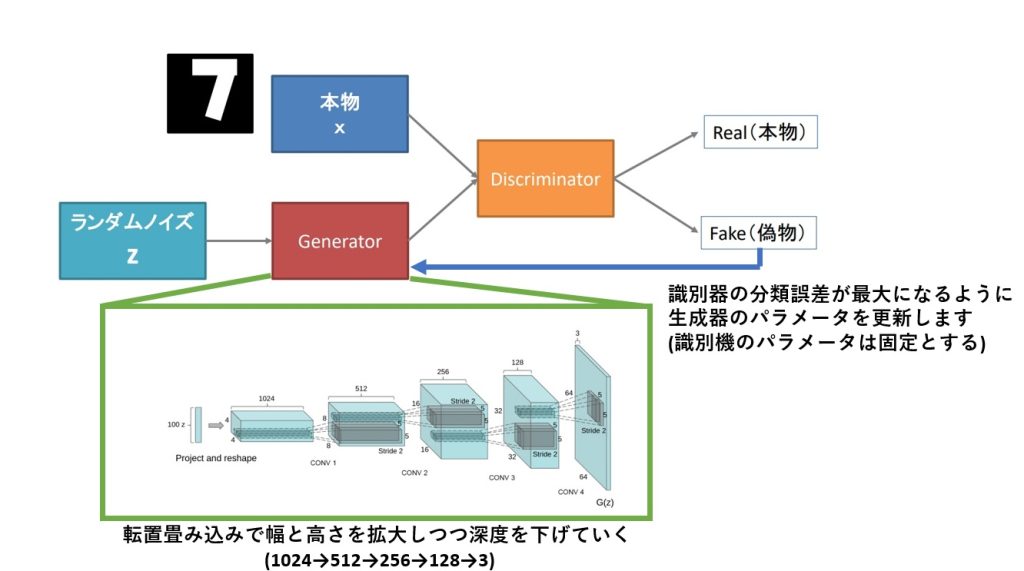
図1 DCGANの原理
少々乱暴ですが理解しやすいように説明すると、DCGANとは【転置畳み込みによってニューロンにランダムノイズの特徴量を学習させることから始まり、識別機(Discriminator)の判定をすり抜けるようなFakeを作り出すように、生成器(Generator)が学習した特徴量を変化させつつFakeを生成する】画像生成モデルであります。
ただし、DCGANでは扱うことのできる画像の最大値が64×64ピクセルのため、更に大きい画像を扱うにはPGGANなどを扱うことになります。
(PGGANについては研究2で扱います)
Hayate.Labに戻る