研究1 : DCGANを用いたAIによる画像生成の体験
・背景と目的
・アプローチ手法
・原理
・可視化方法
・可視化結果
・考察
【アプローチ手法】
既存技術のDCGAN(Deep Convolutional Generative Adversarial Networks)モデルを用いて、風景画(本物:x)を入力とし、ランダムノイズから出力する画像を風景画の特徴を学習させながら生成します。
DCGANの構成イメージを下図に示します。なお、Generatorは「生成器」を意味し、Discriminatorは「判別器」を意味します。
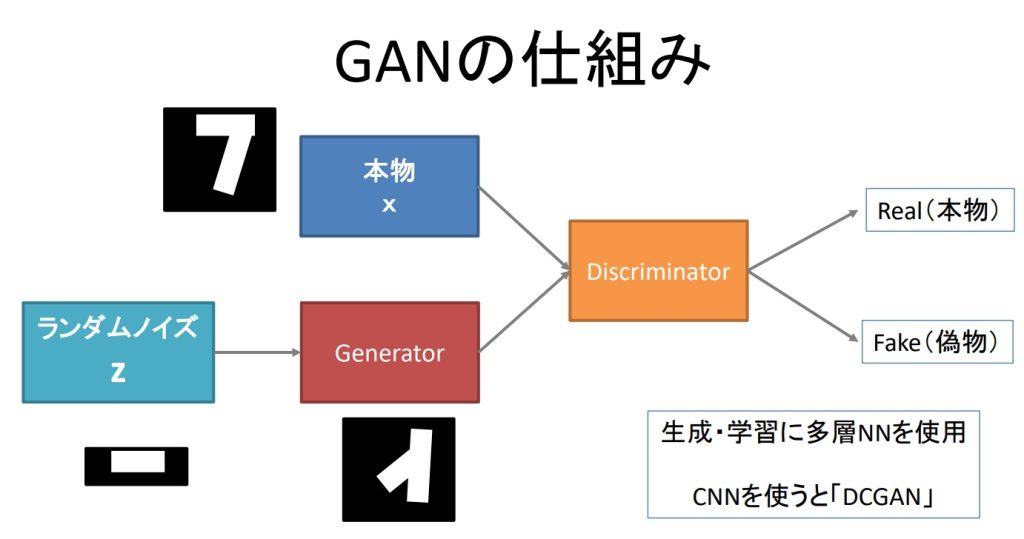
図1 GAN/DCGANのイメージ図
Generator(生成器)から生成される出力となる画像は、下図のように多層の転置畳み込みを経て64✕64ピクセルの画像となります。
畳み込みとは:
1個のニューロンで学習できるパターンは1個だけです。実際の画像をニューラルネットワーク(NN)で特徴を学習しようとすると、各領域の異なるパターンを見つける必要があります。このため、たくさんのニューロンをネットワークに追加する必要があり、この多数のニューロンによって構成される層を畳み込み層と定義づけられています。つまり、畳み込みとは(かなり乱暴な言い方ですが)、入力に対する特徴抽出をニューロンに重み付けして学習させることです。
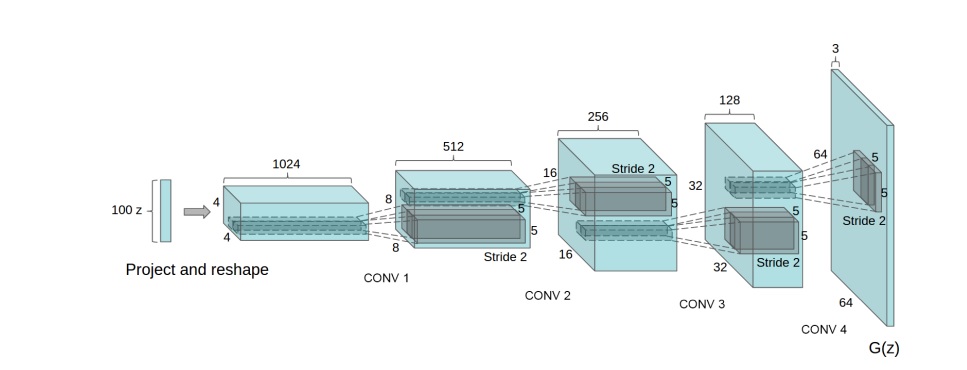
図2 ランダムノイズから畳み込みを繰り返し、64✕64ピクセルの画像を生成するイメージ図
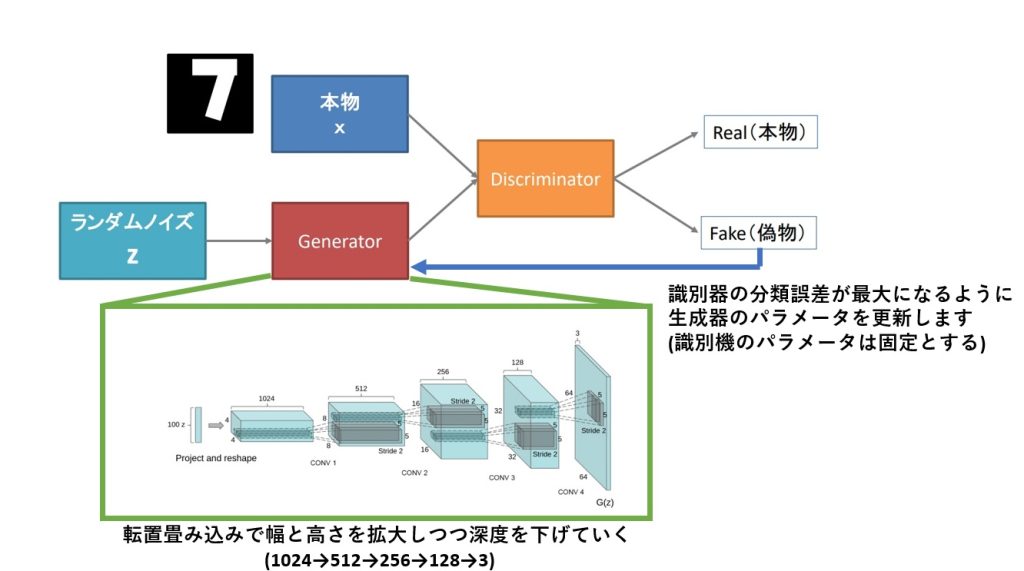
Generatorでの処理について
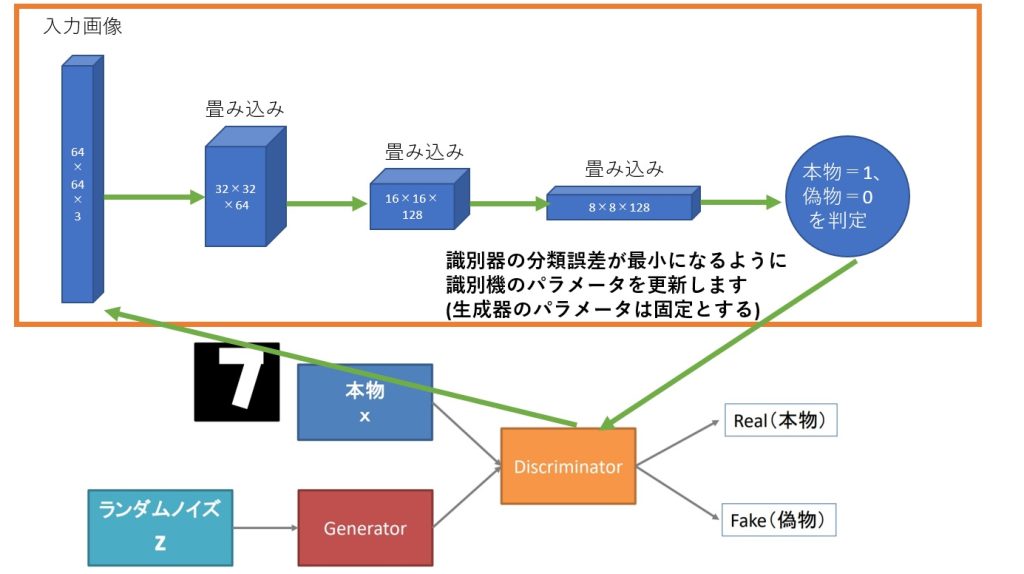
Discriminatorでの処理について
【コード】 (keras 2.9.0)
参考:https://tensorflow.classcat.com/2022/06/29/keras-2-examples-generative-dcgan-overriding-train-step/
#セットアップ
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import numpy as np
import matplotlib.pyplot as plt
#フォルダからデータセットを作成し、画像を [0-1] の範囲にリスケールします :
dataset = keras.preprocessing.image_dataset_from_directory(
"【入力画像フォルダ】", label_mode=None, image_size=(64, 64), batch_size=32
)
dataset = dataset.map(lambda x: x / 255.0)
###Found 202599 files belonging to 1 classes.
#discriminator の作成
#64×64 画像を二値分類スコアにマップします。(数字はピクセル数を指しています)
discriminator = keras.Sequential(
[
keras.Input(shape=(64, 64, 3)),
layers.Conv2D(64, kernel_size=4, strides=2, padding="same"),
layers.LeakyReLU(alpha=0.2),
layers.Conv2D(128, kernel_size=4, strides=2, padding="same"),
layers.LeakyReLU(alpha=0.2),
layers.Conv2D(128, kernel_size=4, strides=2, padding="same"),
layers.LeakyReLU(alpha=0.2),
layers.Flatten(),
layers.Dropout(0.2),
layers.Dense(1, activation="sigmoid")
],
name="discriminator"
)
discriminator.summary()
# 出力結果例:
Model: "discriminator"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 32, 32, 64) 3136
_________________________________________________________________
leaky_re_lu (LeakyReLU) (None, 32, 32, 64) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 16, 16, 128) 131200
_________________________________________________________________
leaky_re_lu_1 (LeakyReLU) (None, 16, 16, 128) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 8, 8, 128) 262272
_________________________________________________________________
leaky_re_lu_2 (LeakyReLU) (None, 8, 8, 128) 0
_________________________________________________________________
flatten (Flatten) (None, 8192) 0
_________________________________________________________________
dropout (Dropout) (None, 8192) 0
_________________________________________________________________
dense (Dense) (None, 1) 8193
=================================================================
Total params: 404,801
Trainable params: 404,801
Non-trainable params: 0
_________________________________________________________________
#generator の作成
#generatorは discriminator をミラーリングしているのでConv2D を Conv2DTranspose 層で置き換えます。
latent_dim = 128
generator = keras.Sequential(
[
keras.Input(shape=(latent_dim,)),
layers.Dense(8 * 8 * 128),
layers.Reshape((8, 8, 128)),
layers.Conv2DTranspose(128, kernel_size=4, strides=2, padding="same"),
layers.LeakyReLU(alpha=0.2),
layers.Conv2DTranspose(256, kernel_size=4, strides=2, padding="same"),
layers.LeakyReLU(alpha=0.2),
layers.Conv2DTranspose(512, kernel_size=4, strides=2, padding="same"),
layers.LeakyReLU(alpha=0.2),
layers.Conv2D(3, kernel_size=5, padding="same", activation="sigmoid")
],
name="generator"
)
generator.summary()
# 出力結果例:
Model: "generator"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 8192) 1056768
_________________________________________________________________
reshape (Reshape) (None, 8, 8, 128) 0
_________________________________________________________________
conv2d_transpose (Conv2DTran (None, 16, 16, 128) 262272
_________________________________________________________________
leaky_re_lu_3 (LeakyReLU) (None, 16, 16, 128) 0
_________________________________________________________________
conv2d_transpose_1 (Conv2DTr (None, 32, 32, 256) 524544
_________________________________________________________________
leaky_re_lu_4 (LeakyReLU) (None, 32, 32, 256) 0
_________________________________________________________________
conv2d_transpose_2 (Conv2DTr (None, 64, 64, 512) 2097664
_________________________________________________________________
leaky_re_lu_5 (LeakyReLU) (None, 64, 64, 512) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 64, 64, 3) 38403
=================================================================
Total params: 3,979,651
Trainable params: 3,979,651
Non-trainable params: 0
_________________________________________________________________
#train_stepのオーバーライド
class GAN(keras.Model):
def __init__(self, discriminator, generator, latent_dim):
super(GAN, self).__init__()
self.discriminator = discriminator
self.generator = generator
self.latent_dim = latent_dim
def compile(self, d_optimizer, g_optimizer, loss_fn):
super(GAN, self).compile()
self.d_optimizer = d_optimizer
self.g_optimizer = g_optimizer
self.loss_fn = loss_fn
self.d_loss_metric = keras.metrics.Mean(name="d_loss")
self.g_loss_metric = keras.metrics.Mean(name="g_loss")
@property
def metrics(self):
return [self.d_loss_metric, self.g_loss_metric]
def train_step(self, real_images):
# Sample random points in the latent space
batch_size = tf.shape(real_images)[0]
random_latent_vectors = tf.random.normal(shape=(batch_size, self.latent_dim))
# Decode them to fake images
generated_images = self.generator(random_latent_vectors)
# Combine them with real images
combined_images = tf.concat([generated_images, real_images], axis=0)
# Assemble labels discriminating real from fake images
labels = tf.concat(
[tf.ones((batch_size, 1)), tf.zeros((batch_size, 1))], axis=0
)
# Add random noise to the labels - important trick!
labels += 0.05 * tf.random.uniform(tf.shape(labels))
# Train the discriminator
with tf.GradientTape() as tape:
predictions = self.discriminator(combined_images)
d_loss = self.loss_fn(labels, predictions)
grads = tape.gradient(d_loss, self.discriminator.trainable_weights)
self.d_optimizer.apply_gradients(
zip(grads, self.discriminator.trainable_weights)
)
# Sample random points in the latent space
random_latent_vectors = tf.random.normal(shape=(batch_size, self.latent_dim))
# Assemble labels that say "all real images"
misleading_labels = tf.zeros((batch_size, 1))
# Train the generator (note that we should *not* update the weights
# of the discriminator)!
with tf.GradientTape() as tape:
predictions = self.discriminator(self.generator(random_latent_vectors))
g_loss = self.loss_fn(misleading_labels, predictions)
grads = tape.gradient(g_loss, self.generator.trainable_weights)
self.g_optimizer.apply_gradients(zip(grads, self.generator.trainable_weights))
# Update metrics
self.d_loss_metric.update_state(d_loss)
self.g_loss_metric.update_state(g_loss)
return {
"d_loss": self.d_loss_metric.result(),
"g_loss": self.g_loss_metric.result(),
}
#生成された画像を定期的にセーブするコールバックの作成
class GANMonitor(keras.callbacks.Callback):
def __init__(self, num_img=3, latent_dim=128):
self.num_img = num_img
self.latent_dim = latent_dim
def on_epoch_end(self, epoch, logs=None):
random_latent_vectors = tf.random.normal(shape=(self.num_img, self.latent_dim))
generated_images = self.model.generator(random_latent_vectors)
generated_images *= 255
generated_images.numpy()
for i in range(self.num_img):
img = keras.preprocessing.image.array_to_img(generated_images[i])
img.save("generated_img_%03d_%d.png" % (epoch, i))
#END-TO-ENDモデルの訓練
epochs = 100 # In practice, use ~100 epochs
gan = GAN(discriminator=discriminator, generator=generator, latent_dim=latent_dim)
gan.compile(
d_optimizer=keras.optimizers.Adam(learning_rate=0.0001),
g_optimizer=keras.optimizers.Adam(learning_rate=0.0001),
loss_fn=keras.losses.BinaryCrossentropy(),
)
gan.fit(
dataset, epochs=epochs, callbacks=[GANMonitor(num_img=10, latent_dim=latent_dim)]
)
以上です。 Hayate.Labに戻る