畳み込みニューラルネットワーク(CNN:Convolutional Neural Networks)について紹介する前に、ここではまず一般的な画像分類問題を例に、基本的な考え方を確認していきます。
画像分類と視覚ニューロン
最もシンプルなケースとして、下図のような手書きの数字の画像を入力値として与えられたとしましょう。これらの画像について、それぞれ0から9の数字のラベルをつけることを考えます。

手書きの数字の画像
人間にとっては、これは簡単な問題です。黒い筆跡による形をみただけで容易に数字を認識することが出来ます。これは私達の脳の中ではすでに、視覚ニューロンとして事前に組み込まれている、異なる形のパターンを認識する機能が備わっているからだと考えられます。
このことから、神経科学の分野での視覚ニューロンの研究に触発される形で、コンピュータ科学の分野でも、それと似た構造のニューラルネットワークを作りたいと考えました。脳の中の視覚ニューロンと同じような機能を再現しようと考えたわけです。
このような種類のニューラルネットワークのことを畳み込みニューラルネットワーク(CNN:Convolutional Neural Network)と呼びます。CNNは畳み込み(convolution)と呼ばれる階層感をつなぐ特徴があります。実際、この畳込みと呼ばれる構造は、視覚ニューロンのうち、最も価値のある構造と言えます。
1個のニューロンに入力画像全体を学習させる
畳み込みの構造を理解するために、手書き文字で数字の「5」の画像を入力とするCNNニューロン構造のシンプルな例を下図でみてみましょう。前の章(③ニューラルネットワークの基礎 )で説明したネットワークの構造は、すべての画素(pixel)を1個のニューロンの入力とする全結合の構造でしたが、CNNでは1個のニューロンには、画像の一部が直接入力されます。CNNでは、画像の中の小さな領域(青い四角で囲まれた領域)にフォーカスして、1個のニューロンは図(b)のように3✕3の範囲の画素(9pixel)だけに結合します。わかりやすくするために、入力画像の全体を図(a)に、1個のニューロンに対応する部分を図(b)で拡大表示しています。
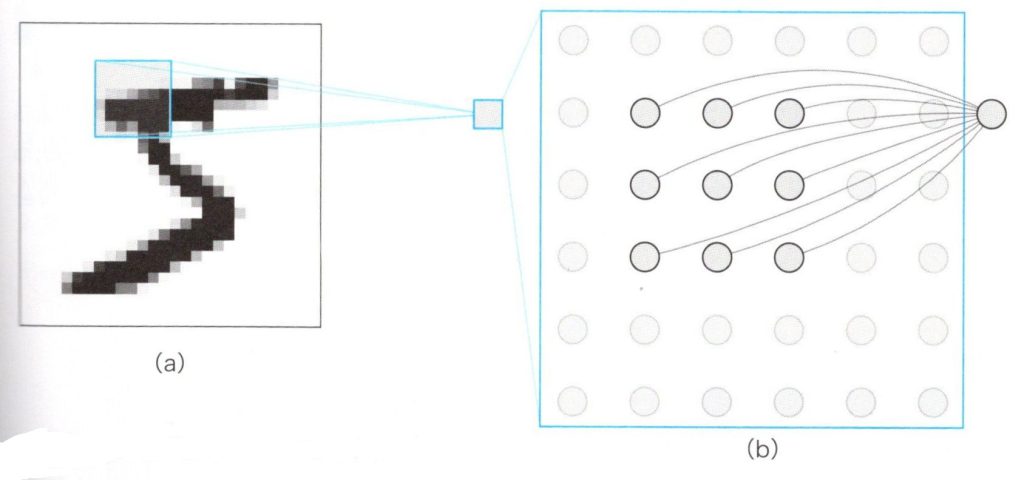
CNNの局所的なコネクション
部分的に結合する構造はシンプルですが、画像から部分的な特徴を学習するだけでは十分とは言えません。CNNでは、別の場所に出てくる同じパターンを見つける必要があります。このために、すべての場所に対応するニューロンを用意するのは無駄なニューロンをたくさん使うことになるので、あまり採用したくありません。かわりに注目する場所を移動させることで、同じニューロンを使いまわすことを考えます。下図ではその様子を表しており、入力画像野中のフォーカスした領域を移動することで、1個のニューロンに対して入力する3✕3の画素の内容を更新し、入力画像全体をを学習させています。
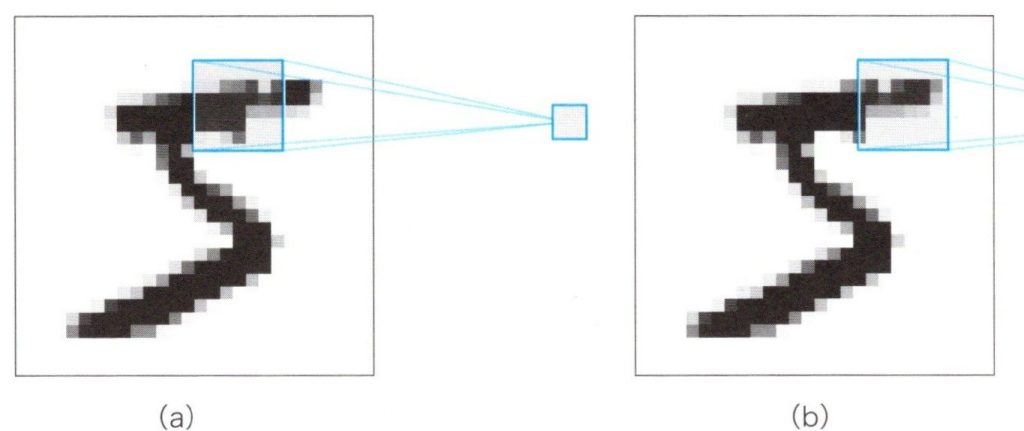
フォーカスの移動
もちろん、青い四角の通るルートは、自分で好きなように設定できます。しかしながら、広く受け入れられたシステマティックな方法としては、左から右、上から下に、青い四角を滑るように移動させるスライディングと呼ばれる方法があります。こうすることで、1個のニューロンに入力画像全体を学習させる方法を「畳み込み」と呼んでいます。この方法で学習させるニューラルネットワークのことを畳み込みニューラルネットワーク(CNN)と呼びます。
下図(a)は、何万もの異なる手書き数字の学習をした後、1個のニューロンから出力されるパターンです。実際には上部が暗く下部が明るい小さなカーブを表しています。下図(b)は入力画像を畳み込んで入力した時、1個のニューロンがどんな出力をするかを示しています。
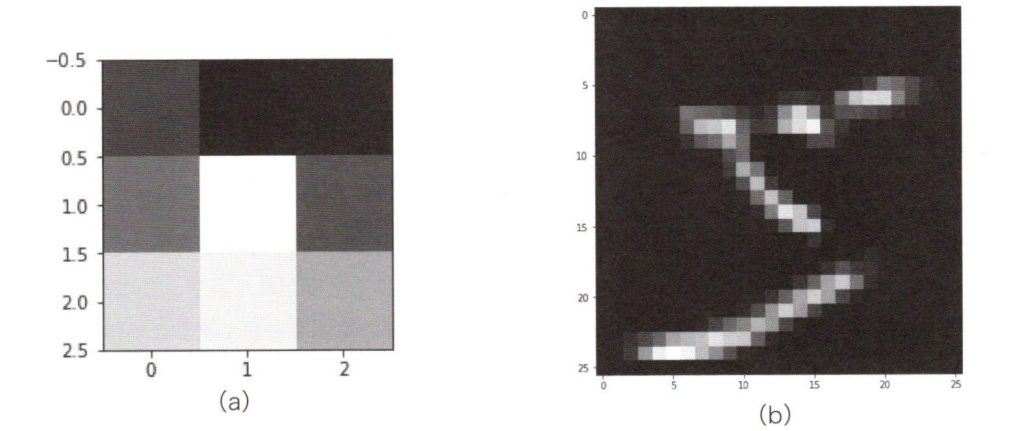
畳み込みで学習したニューロンの出力
画像の中の多くの部分は、このニューロンが学習したパターンとは違って見えますが、そのような場合ではニューロンは発火せず、小さな出力値となるため、暗い領域になります。画像の中の一部の部分では、このニューロンが学習したパターンと似ているため、ニューロンは発火して大きな出力値となり、明るい部分が出来ています。