1.概要
この論文は、GPT-3という大規模言語モデルについての研究です。GPT-3は、トレーニングに1750億のパラメータを使用しており、多様な自然言語タスクにおいて優れたパフォーマンスを発揮することが示されました。また、トレーニング後に生成されるコンテンツのエネルギー効率性にも優れています。ただし、GPT-3にはいくつかの課題が残っており、特にバイアスや公正性の問題に対処する必要があることが指摘されています。今後の研究では、これらの課題に取り組むことが求められます。
2.Introduction
この論文のIntroductionでは、大規模言語モデルの重要性(*1)について説明されています。また、GPT-3という大規模言語モデルがどのようにトレーニングされたか(*2)、そしてGPT-3がどのような自然言語タスクにおいて優れたパフォーマンスを発揮するかについても概説されています。さらに、GPT-3が持つ可能性(*3)や限界(*4)についても議論されています。最後に、本研究が自然言語処理分野における新しい進展をもたらすことを期待している旨が述べられています。
*1 大規模言語モデルの重要性
大規模言語モデルは、自然言語処理分野において非常に重要な役割を果たしています。これらのモデルは、トレーニングに大量のテキストデータを使用することで、自然言語タスクにおいて高度なパフォーマンスを発揮することができます。例えば、文章生成や質問応答などのタスクにおいて、大規模言語モデルは人間と同等以上の精度を達成することができます。また、大規模言語モデルは、機械翻訳や対話システムなどの応用分野でも有用です。これらの応用分野では、より高度な自然言語処理技術が求められており、大規模言語モデルはそのような要求に応えるために開発されました。
*2 GPT-3はどのようにトレーニングされたのか?
GPT-3は、トレーニングに1750億のパラメータを使用した大規模言語モデルです。トレーニングには、多様なテキストデータが使用されました。具体的には、ウェブページ、書籍、ニュース記事、科学論文などのテキストデータが使用されました。トレーニング自体は、教師なし学習アルゴリズムである自己回帰型言語モデルを使用して行われました。このアルゴリズムでは、モデルは与えられたテキストシーケンスから次の単語を予測するようにトレーニングされます。このようにしてトレーニングされたGPT-3は、多様な自然言語タスクにおいて優れたパフォーマンスを発揮することができます。
*3 GPT-3が持つ可能性
GPT-3は、多様な自然言語タスクにおいて優れたパフォーマンスを発揮することができるため、多くの可能性を秘めています。例えば、文章生成や質問応答などのタスクにおいて、GPT-3は人間と同等以上の精度を達成することができます。また、GPT-3は、機械翻訳や対話システムなどの応用分野でも有用です。さらに、GPT-3は、少量のトレーニングデータで高いパフォーマンスを発揮することができるため、新しいタスクに対しても柔軟に適用することができます。これらの特徴から、GPT-3は自然言語処理分野における新しい進展をもたらす可能性があります。
*4 GPT-3の限界
GPT-3は、多くの自然言語タスクにおいて優れたパフォーマンスを発揮する一方で、いくつかの限界も持っています。例えば、GPT-3は文章生成において高品質な文章を生成することができますが、長い文章になると意味のつながりが失われたり、矛盾した文章を生成することがあります。また、GPT-3は一部の自然言語タスクにおいて苦手な場合もあります。さらに、GPT-3は大量のウェブコーパスからトレーニングされたため、その中には不適切な表現や偏った情報が含まれる可能性があります。これらの限界を克服するためには、今後も研究者や開発者が新しい手法やアルゴリズムを開発していく必要があります。
3. Approach
3.1 Fine-Tuning (FT)
近年の機械学習において最も一般的な手法の1つであり、事前にトレーニングされたモデルの重みを、特定のタスクに合わせて微調整する手法です。Fine-Tuningでは、特定のタスクに関連する大量のラベル付きデータを使用します。この手法は、多くのベンチマークで高いパフォーマンスを発揮することができますが、新しいタスクごとに大量のラベル付きデータが必要であるため、実際の応用においてはコストがかかる場合があります。また、Fine-Tuningではトレーニングデータに偏りがある場合や未知のデータに対して汎化性能が低下する可能性があるため、注意が必要です。
3.2 Few-Shot
事前にトレーニングされたモデルを使用して、ごく少数の例文やクエリを入力し、そのタスクに対するモデルを学習します。Few-Shotは、Fine-Tuningよりも少ないラベル付きデータで高いパフォーマンスを発揮することができますが、Fine-Tuningよりも高度な技術やアルゴリズムが必要である場合があります。Few-Shotは、人間の学習能力に近いとされており、将来的にはより柔軟で効率的な機械学習手法として注目されています。
3.3 One-Shot
機械学習において、たった1つのラベル付きデータを使用して、新しいタスクに対するモデルをトレーニングする手法です。One-Shotでは、事前にトレーニングされたモデルを使用して、1つの例文やクエリを入力し、そのタスクに対するモデルを学習します。One-Shotは、Few-Shotよりもさらに少ないラベル付きデータで高いパフォーマンスを発揮することができますが、Fine-TuningやFew-Shotよりも高度な技術やアルゴリズムが必要である場合があります。One-Shotは、非常に限られたラベル付きデータしか利用できない場合や、新しいタスクが急に発生した場合などに有用です。
3.4 Zero-Shot
機械学習において、ラベル付きデータを使用せずに新しいタスクに対するモデルをトレーニングする手法です。Zero-Shotでは、自然言語で記述されたタスクの説明が与えられますが、具体的な例文やクエリは与えられません。Zero-Shotは、最大限の利便性、堅牢性の可能性、および偽の相関を回避する可能性を提供します(前処理データの大規模なコーパス全体で広く発生する場合を除く)。しかし、この手法は最も難しい設定であり、人間でも事前の例がないとタスクの形式を理解することが困難な場合があるため、「不公平に難しい」とされています。Zero-Shotは、実際の応用において非常に有用であり、将来的にはより柔軟で効率的な機械学習手法として注目されています。

図1
図1は、GPT-3におけるZero-Shot、One-Shot、Few-Shotの手法を伝統的なFine-Tuningと比較したものです。図の上部には、言語モデルを使用してタスクを実行する4つの方法が示されています。Fine-Tuningは従来の方法であり、Zero-Shot、One-Shot、Few-Shotはそれぞれトレーニング時にラベル付きデータを使用しない手法です。これらの手法では、テスト時にモデルがタスクを実行するために必要な情報が与えられます。Few-Shotでは通常数十個の例文が与えられます。図1は、GPT-3におけるZero-Shot、One-Shot、Few-Shotの手法がどのように機能するかを示しています。
4.1 Model and Architectures
GPT-3は、GPT-2と同じモデルとアーキテクチャを使用していますが、トランスフォーマーのレイヤーに交互に密な層と局所的にバンドされた疎な注意パターンを使用しています。これはSparse Transformerと呼ばれる手法に類似しています。また、GPT-3では、モデルサイズによるMLパフォーマンスの依存関係を調べるために、125万から1750億まで8つの異なるモデルサイズをトレーニングしています。
4.2 Training Dataset
言語モデルのトレーニングに使用されるデータセットについて説明されています。最近の言語モデルでは、Common Crawlデータセットが使用されており、これはほぼ1兆語を含むものです。しかし、Common Crawlの未加工または軽度にフィルタリングされたバージョンは、より厳選されたデータセットよりも品質が低いことがわかっています。そのため、GPT-3では、Common Crawlをより厳選したウェブコーパスや書籍などのデータセットを使用しています。また、GPT-3では、トレーニング時にラベル付きデータを使用しないZero-Shot学習を行うために、さまざまなタスクに関連する大量のテキストを収集することも行っています。
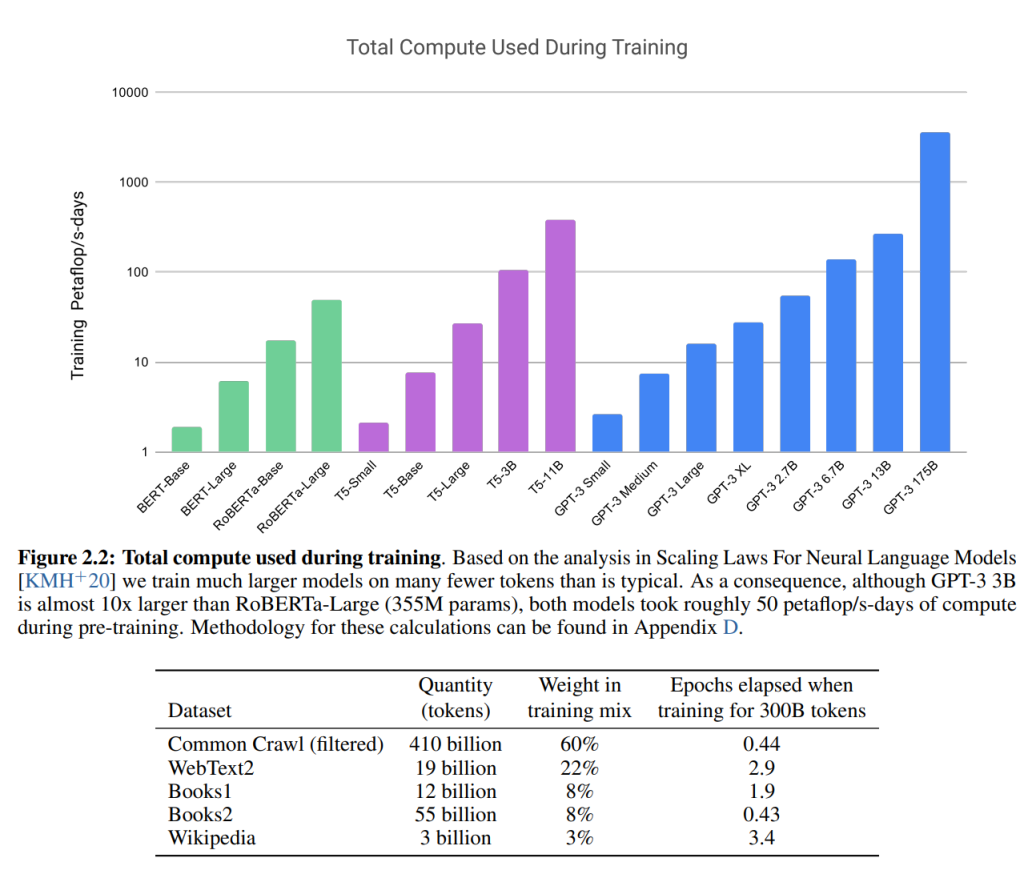
4.3 Training Process
GPT-3のトレーニングプロセスについて説明すます。GPT-3は、大規模な分散トレーニングを使用してトレーニングされており、多数のGPUとTPUを使用します。トレーニングプロセスは、事前学習とファインチューニングの2つの段階に分かれています。事前学習では、大量のテキストデータを使用してモデルをトレーニングし、ファインチューニングでは、特定のタスクに適したより小さなデータセットでモデルを調整します。また、GPT-3では、学習率やバッチサイズなどのハイパーパラメーターを最適化するために多くの実験が行われれてきた経緯があります。
4.4 Evaluation
GPT-3は、多数のNLPタスクに対して評価されました。これらのタスクには、翻訳、質問応答、穴埋め問題などが含まれます。また、GPT-3は、新しい単語を文章に組み込むなどのタスクも実行できます。さらに、GPT-3はZero-Shot学習を使用しており、トレーニング時にラベル付きデータを使用しなくても多くのタスクで高いパフォーマンスを発揮することができます。
5. Measuring and Preventing Memorization Of Benchmarks
トレーニングデータセットがインターネットから取得された場合、モデルがベンチマークテストセットの一部でトレーニングされた可能性があるため、テスト汚染を正確に検出することが重要です。 この問題に対処するために、論文では2つの手法が提案されています。1つ目は、トレーニングデータセットからランダムにサンプリングした小さなサブセットを使用してモデルをトレーニングし、その後、残りのデータセットでファインチューニングする方法です。これにより、モデルが特定のテストセットを完全に記憶することを防ぐことができます。 2つ目は、「ダイバーシティペナルティ」と呼ばれる手法であり、トレーニング時に多様性を促進することで記憶化を防止します。具体的には、トレーニング時に生成された文章の多様性を測定し、多様性が低い場合はペナルティを課します。これにより、モデルが特定のテストセットを完全に記憶することを防ぐことができます。 しかし、インターネットスケールのデータセットからテスト汚染を正確に検出する方法はまだ確立されておらず、最適な方法は不明です。
6. Limitations
GPT-3とその分析にはいくつかの制限があることが説明されています。これらの制限には、以下のようなものが含まれます。
1. データ汚染に関する問題:インターネットスケールのデータセットからトレーニングされたモデルは、テス
トセットを完全に記憶する可能性があります。この問題を解決するために、論文では2つの手法が提案され
ています(5章参照)。
2. Zero-Shot学習に関する問題:Zero-Shot学習は、ラベル付きデータを使用しなくても多くのタスクで高いパ
フォーマンスを発揮できますが、一部のタスクではまだ改善の余地があります。
3. メモリ使用量に関する問題:GPT-3は非常に大きなモデルであり、メモリ使用量が非常に高いため、一部の
システムでは実行できない場合があります。
4. 計算コストに関する問題:GPT-3は非常に大規模なモデルであり、トレーニングや推論に多大な計算コスト
がかかります。 5. データセットの偏りに関する問題:GPT-3は、インターネットから収集されたデータセッ
トを使用してトレーニングされているため、一部のデータセットに偏りがある可能性があります。
7. Broader Impacts
この章では、GPT-3が持つ広範な影響について議論されています。この節では、GPT-3が持つ可能性のある悪影響についても言及されています。 具体的には、以下のような問題が挙げられています。
1. 意図的な誤用:GPT-3は非常に高度な自然言語処理能力を持っており、悪意のある人々がこれを利用して偽
情報を拡散する可能性があります。
2. バイアスや公平性の問題:GPT-3は大量のデータからトレーニングされるため、バイアスや公平性の問題が
生じる可能性があります。例えば、特定の人種やジェンダーに対する偏見を含む文章を生成することがあり
ます。
3. エネルギー効率の問題:GPT-3は非常に大きなモデルであり、トレーニングや推論に多大な計算コストがか
かります。これはエネルギー消費量の増加につながります。
8. Related Work
この章では、GPT-3に関連する過去の研究について説明されています。GPT-3と同様に大規模な自然言語処理モデルや、Zero-Shot学習などの手法が紹介されています。 具体的には、以下のような研究が挙げられています。
1. BERT:BERTは、Googleが開発した自然言語処理モデルであり、GPT-3と同様にTransformerモデルを採用しています。BERTは多くの自然言語処理タスクで高いパフォーマンスを発揮しました。
2. T5:T5は、Googleが開発した自然言語処理モデルであり、GPT-3と同様に大規模なトレーニングデータセットを使用しています。T5は多くの自然言語処理タスクで高いパフォーマンスを発揮しました。
3. Zero-Shot学習:Zero-Shot学習は、ラベル付きデータを使用しなくても多くのタスクで高いパフォーマンスを発揮することができる手法です。GPT-3はZero-Shot学習に非常に適しており、その高いパフォーマンスにつながっています。
9. Conclusion
Conclusionでは、GPT-3が持つ可能性のある利点や課題についてまとめられています。 具体的には、以下のようなことが述べられています。
1. GPT-3は、多くの自然言語処理タスクで高いパフォーマンスを発揮することができる。
2. GPT-3は、Zero-Shot学習に非常に適しており、ラベル付きデータを使用しなくても多くのタスクで高いパフォーマンスを発揮することができる。
3. GPT-3は、大規模なトレーニングデータセットを使用してトレーニングされるため、バイアスや公平性の問
題が生じる可能性がある。
これらの問題に対処するためには、より多様なトレーニングデータセットを使用したり、モデル内部でバイ
アスを減らすための手法を開発したりする必要がある。
4. GPT-3は、さまざまな分野で応用される可能性があり、特に自然言語処理分野において大きな進歩をもたら
すことが期待される。