1.概要
この論文は、大規模言語モデルの重要性と可能性について議論するものです。提案されたモデルは、自然言語処理タスクにおいて、従来の手法よりも優れたパフォーマンスを発揮することが示されています。また、提案されたモデルは、ゼロショット学習(*)によって新しいタスクを学習できることが示されており、将来的には人間のような自然言語理解を実現する可能性があります。ただし、提案されたモデルは非常に大規模であり、トレーニングには多大なコンピューティングリソースが必要です。また、WebTextなどの大規模なテキストコーパスからトレーニングする場合、データ品質問題が生じる可能性があるため注意が必要です。最後に、提案されたモデルを使用して構築された自然言語処理システムは、現在の人工知能技術の限界を超える可能性があることが示唆されています。
*ゼロショット学習:
ゼロショット学習とは、あるタスクに対して事前のトレーニングを行わずに、新しいタスクを学習することができる機械学習の手法です。つまり、新しいタスクに対して事前のトレーニングデータがなくても、既存の知識や情報を利用して新しいタスクを解決することができます。この手法は、人間が新しいタスクを解決する際にも用いられる能力に似ており、自然言語処理などの分野で有用性が高く注目されています。この論文では、大規模言語モデルを使用したゼロショット学習の可能性について議論されています。
2.Approach
この章では、言語モデルを用いて自然言語のシーケンスを学習することで、ゼロショット学習を可能にすることについて触れています。式1は、言語モデルにおける条件付き確率分布を表しています。この式では、シーケンス全体の確率分布を、各シンボルの条件付き確率分布の積として表現しています。具体的には、s1からsnまでのシンボルが与えられたときに、sn+1の確率を求めるために、s1からsnまでのすべてのシンボルに対する条件付き確率分布を掛け合わせます。これにより、任意の条件付き確率分布を容易にサンプリングしたり推定したりすることができます。このアプローチは、自然言語処理タスクにおいて高いパフォーマンスを発揮し、ゼロショット学習にも適していることが示されています。
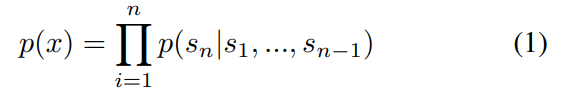
2.1 Training Dataset
ここでは本論文で使用されたトレーニングデータセットについて説明しています。従来の手法では、ニュース記事やWikipediaなどの単一ドメインのテキストを用いて言語モデルをトレーニングすることが一般的でしたが、本論文では、多様なドメインやコンテキストから自然言語のデモンストレーションを収集することを目的としています。そのため、Common CrawlなどのWebスクレイピングによる大規模なテキストコーパスが有望なソースとして挙げられています。ただし、これらのアーカイブは現在の言語モデリングデータセットよりもはるかに大きく、データ品質問題が含まれている、という前提で扱います。
2.2 Input Representation
ここでは、本論文で使用された入力表現について説明します。一般的な言語モデルは、任意の文字列の確率を計算することができる必要があります。しかし、現在の大規模言語モデルでは、小文字化、トークン化、未知語トークンなどの前処理ステップが含まれており、モデル可能な文字列の範囲が制限されています。Unicode文字列をUTF-8バイトのシーケンスとして処理する方法は、先行研究で示されているように、この要件を優雅に満たすことができます。ただし、現在のバイトレベル言語モデルは、大規模データセットでは単語レベル言語モデルに比べて競争力が劣っていることが報告されています。WebText上で標準的なバイトレベル言語モデルをトレーニングした場合でも同様のパフォーマンスギャップが観察されました。
2.3 Model
本論文で提案するモデルは、Transformerアーキテクチャを基盤としており、多層のエンコーダーとデコーダーから構成されています。エンコーダーは、入力シーケンスを処理し、隠れ状態を生成します。デコーダーは、エンコーダーからの情報とターゲットシーケンスを使用して、次のトークンを予測します。このモデルは、大規模なトレーニングセットで事前トレーニングされます。その後、ゼロショット学習に使用するために微調整されます。本論文では、GPT-2と呼ばれる3つの異なるサイズのモデルが提案されており、それぞれ1.5B, 774M, 355M個のパラメータを持っています。これらのモデルはすべて非常に高いパフォーマンスを発揮し、自然言語処理タスクにおいて最先端の結果を達成しています。
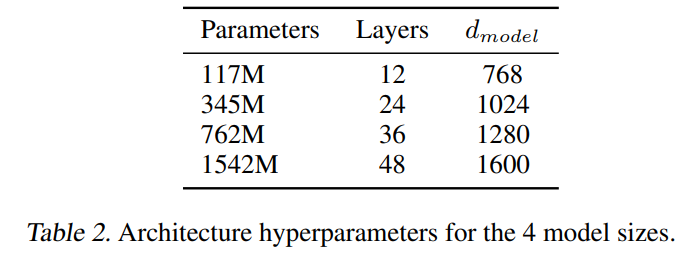
下記の表1は、GPT-2モデルのアーキテクチャに関する情報を示す表です。この表には、4つの異なるモデルサイズ(117M、345M、762M、1542M)に対するアーキテクチャのハイパーパラメータが示されています。これらのパラメータには、レイヤー数、隠れ層サイズ、エンベッドサイズなどが含まれます。最も小さいモデルは元のGPTと同等であり、2番目に小さいモデルはBERTの最大モデルと同等です。最大のモデルであるGPT-2は、GPTよりも1桁以上多くのパラメータを持っています。これらのアーキテクチャパラメータは、それぞれのモデルサイズに応じて調整されており、それぞれが高い性能を発揮しています。
3.Generalization vs Memorization
ここでは、本論文で言及された一般化と記憶の問題について説明しています。コンピュータビジョンの分野において、一般的な画像データセットには、非常に似た画像が含まれていることが報告されています。これは、機械学習システムの一般化性能を過大評価することにつながります。同様の現象がWebTextでも起こっている可能性があるため、トレーニングデータとテストデータの重複率を分析することが重要です。本論文では、CIFAR-10データセットで3.3%の重複率が報告されており、これは問題を引き起こす可能性があることを示唆しています。この問題は、データセットサイズが増加するにつれてますます深刻になるため、注意深く分析する必要があります。
4.Related Work
このセクションでは、言語モデルのトレーニングに関する従来のアプローチについて説明し、それらのアプローチがどのようにGPT-2モデルと比較されるかを示しています。従来のアプローチには、単一ドメインのテキスト(ニュース記事、ウィキペディア、小説など)を使用したトレーニングが含まれます。これらのアプローチは、特定のドメインで高いパフォーマンスを発揮することができますが、他のドメインでは劣る場合があります。一方、GPT-2モデルはWebTextと呼ばれる非常に大規模なトレーニングセットを使用してトレーニングされており、多様なドメインから収集された自然言語表現を含んでいます。この方法論は、GPT-2モデルが多様なタスクで高いパフォーマンスを発揮することを可能にしました。また、「Related Work」では、ゼロショット学習や転移学習などの関連技術も紹介されています。
5.レガシーな(従来の)自然言語処理とGPT2との比較
従来の自然言語処理では、単一ドメインのテキストを使用してトレーニングされたモデルが一般的でした。これらのモデルは、特定のドメインで高いパフォーマンスを発揮することができますが、他のドメインでは劣る場合があります。また、従来の手法では、事前にラベル付けされた大規模なデータセットが必要であり、その作成には多大なコストがかかります。
一方、GPT-2モデルはWebTextと呼ばれる非常に大規模なトレーニングセットを使用してトレーニングされており、多様なドメインから収集された自然言語表現を含んでいます。この方法論は、GPT-2モデルが多様なタスクで高いパフォーマンスを発揮することを可能にしました。また、GPT-2モデルはゼロショット学習にも対応しており、新しいタスクに対して事前トレーニングされたモデルを使用することで、高いパフォーマンスを発揮することができます。 GPT-2モデルの性能向上には、大規模なトレーニングセットの使用、より深いニューラルネットワークの使用、およびトレーニングプロセスの最適化が含まれます。これらの改善により、GPT-2モデルは、従来の自然言語処理モデルと比較して、より自然な文章を生成することができます。また、GPT-2モデルは、多様なタスクに対して高いパフォーマンスを発揮することができます。例えば、文書生成、質問応答、要約生成などのタスクにおいて、GPT-2モデルは最先端の性能を発揮しています。
さらに、「Fine-tuning」や「Prompt Engineering」といった手法も開発されており、これらを使用することでGPT-2モデルの性能を更に向上させることができます。Fine-tuningでは、事前トレーニングされたGPT-2モデルを特定のタスクに適応させることで、高いパフォーマンスを発揮することができます。Prompt Engineeringでは、入力文や出力文に特定のキーワードやフレーズを含めることで、より正確な結果を得ることができます。
総じて言えることは、「レガシーな(従来の)自然言語処理」とGPT-2モデルはアプローチ方法が異なりますが、GPT-2モデルは大規模なトレーニングセットを使用し、より深いニューラルネットワークを採用することで、従来の自然言語処理モデルよりも高い性能を発揮することに寄与しています。
6.Discussion
ここでは本論文の結果について議論しています。以下は、そのまとめです。
– GPT-2モデルは、多様なタスクに対して高いパフォーマンスを発揮することができる。
– GPT-2モデルは、大規模なトレーニングセットを使用することで性能が向上する。
– GPT-2モデルは、ゼロショット学習にも対応しており、新しいタスクに対して事前トレーニングされたモデル
を使用することで高いパフォーマンスを発揮することができる。
– Fine-tuningやPrompt Engineeringなどの手法を使用することで、GPT-2モデルの性能を更に向上させること
ができる。
– 一方で、GPT-2モデルの生成結果には偏りがある場合があり、その解決策としてより多様なトレーニングセッ
トの使用やサンプリング方法の改善が必要である。
以上が、「Discussion」セクションのまとめです。GPT-2モデルは非常に高い性能を持ちますが、その生成結果に偏りがある場合もあるため、今後も改善策を模索する必要があります。
7.Conclusion
従来の方法と比較して、GPT2では性能を向上できたが、GPT-2モデルの生成結果に偏りがある場合もあるため、より多様なトレーニングセットの使用やサンプリング方法の改善が必要である。
今後は、GPT-2モデルの性能向上や偏り解消策の開発だけでなく、より大規模なトレーニングセットや新しいアーキテクチャーの開発も重要である。
GPT-2モデルは、自然言語処理において非常に高い性能を発揮することができますが、その生成結果に偏り
がある場合もあるため、今後も改善策を模索する必要があります。また、より大規模なトレーニングセットや新しいアーキテクチャーの開発も重要であるとされています。