1.Introduction
この論文は、自然言語処理タスクにおいて事前トレーニング済みモデルを使用することで、高い精度を達成する方法を提案しています。著者らは、大規模なコーパスで事前トレーニングされたモデルを、さまざまな自然言語処理タスクに適用しました。その結果、事前トレーニング済みモデルは、多くのタスクで最先端の性能を発揮しました。また、転移学習により、小規模なデータセットでも高い精度を達成できることが示されました。さらに、ゼロショット動作においても有用であることが示されました。本研究で提案された方法は、自然言語処理タスクにおける現在の最先端技術を超える性能を発揮することが示されました。
2.Related Work
2.1 Semi-supervised learning for NLP
半教師あり学習は、ラベル付きデータが限られている場合でも、未ラベルのデータを使用してモデルをトレーニングすることができます。このパラダイムは、シーケンスラベリングやテキスト分類などのタスクに適用されており、未ラベルのデータを使用して単語レベルまたはフレーズレベルの統計情報を計算し、これらを監視されたタスクの特徴量として使用する方法が初期アプローチでした。近年では、未ラベルコーパスでトレーニングされた単語埋め込みを使用することで、より高度な性能向上が実現されています。本研究では、事前トレーニング済みモデルを使用することで、自然言語処理タスクにおける最先端の性能を発揮する方法を提案しています。
2.2 Unsupervised pre-training
事前トレーニングは、教師あり学習の目的を変更することなく、良好な初期化点を見つけることを目的とした半教師あり学習の特別なケースです。初期の研究では、画像分類や回帰タスクでこの技術が使用されました。その後の研究では、事前トレーニングが正則化スキームとして機能し、深層ニューラルネットワークでの汎化性能を向上させることが示されました。最近の研究では、この方法が画像分類、音声認識、エンティティ曖昧性解消、機械翻訳などのタスクで使用されています。本論文では、自然言語処理タスクにおいて事前トレーニング済みモデルを使用することで高い精度を達成する方法を提案しています。
3.3 Auxiliary training objectives
この論文では、補助的な教師あり学習目的を追加することで、半教師あり学習の代替手段としての補助的なトレーニング目的について説明しています。初期の研究では、POSタグ付け、チャンキング、名前付きエンティティ認識、言語モデリングなどの様々なNLPタスクが使用され、意味役割ラベリングの改善が実証されました。最近の研究では、対象タスク目的に補助言語モデリング目的を追加し、シーケンスラベリングタスクで性能向上を実証しました。本論文でも補助目的が使用されていますが、事前トレーニング済みモデルはすでに対象タスクに関連する言語的側面を学習しているため、高い精度を発揮することが示されています。
3.Framework
筆者らのトレーニング手順は2つのステージで構成されています。最初のステージは、大規模なテキストコーパス上で高容量の言語モデルを学習することです。これに続いて、ラベル付きデータを使用してモデルを識別タスクに適応させる微調整ステージがあります。
3.1 Unsupervised pre-training
半教師あり学習の最初のステージである事前トレーニングについて説明されています。このステージでは、文脈ウィンドウのサイズkと条件付き確率Pを使用して、ニューラルネットワークパラメータΘを用いた2つの式を最大化します。1つ目の式は、未ラベルのトークンコーパスU = {u1, …, un}に対する標準的な言語モデリング目的であり、次式で表されます。
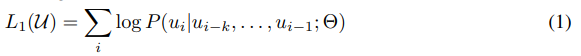
具体的には、文脈ウィンドウのサイズkと条件付き確率Pを使用して、ニューラルネットワークパラメータΘを用いた次式の対数尤度を最大化します。これらのパラメータは、確率勾配降下法[51]を使用してトレーニングされます。このようにして得られた高容量言語モデルは、微調整ステージで識別タスクに適応するために使用されます。
2つ目の式は、微調整ステージで使用される識別タスクに関連するラベル付きデータセットD = {(x1, y1), …, (xm, ym)}に対する損失関数であり、次式で表されます。
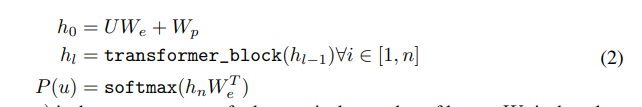
これらの式を最大化することにより、高容量言語モデルが得られます。
3.2 Supervised fine-tuning
ここでは、半教師あり学習の2番目のステージである微調整について説明しています。このステージでは、ラベル付きデータセットD = {(x1, y1), …, (xm, ym)}を使用して、損失関数L2(D)を最小化するようにニューラルネットワークパラメータΘを微調整します。
図1では、多様な識別タスクとデータセットが示されています。これらのタスクとデータセットはGLUEマルチタスクベンチマーク[の一部であり、自然言語推論、質問応答、意味的類似性、テキスト分類などが含まれています。これらのタスクに対して、事前トレーニングで得られた高容量言語モデルを微調整することで、高い精度が得られることが示されています。 式(3)は、微調整ステージで使用される識別タスクに関連するラベル付きデータセットD = {(x1, y1), …, (xm, ym)}に対する損失関数であり、次式で表されます。
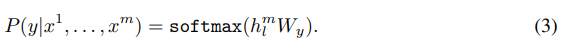
ここで、Pは条件付き確率を表し、式(3)は、入力トークンx1,…,xmに対して正解のラベルyの条件付き確率を表します。この条件付き確率は、ニューラルネットワークの最終層である線形出力層によって計算されます。具体的には、入力トークンx1,…,xmを事前トレーニングで得られた高容量言語モデルに通し、最終的なトランスフォーマーブロックのアクティベーションhm_lを取得します。そして、このアクティベーションhm_lを線形出力層に入力し、パラメータWyを用いて正解のラベルyの条件付き確率P(y|x1,…,xm)を計算します。 式(4)は、損失関数L2(D)を最小化するために使用される交差エントロピー損失関数です。
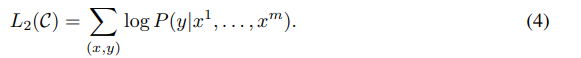
ここで、y^iはi番目の入力トークンxiに対する予測されたラベルであり、yiは正解のラベルです。 式(5)は、微調整ステージで使用される勾配降下法アルゴリズムです。ここでは、損失関数L2(D)を最小化するためにニューラルネットワークパラメータΘを更新します。具体的には、損失関数の勾配を計算し、学習率を用いてパラメータΘを更新します。
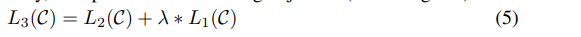
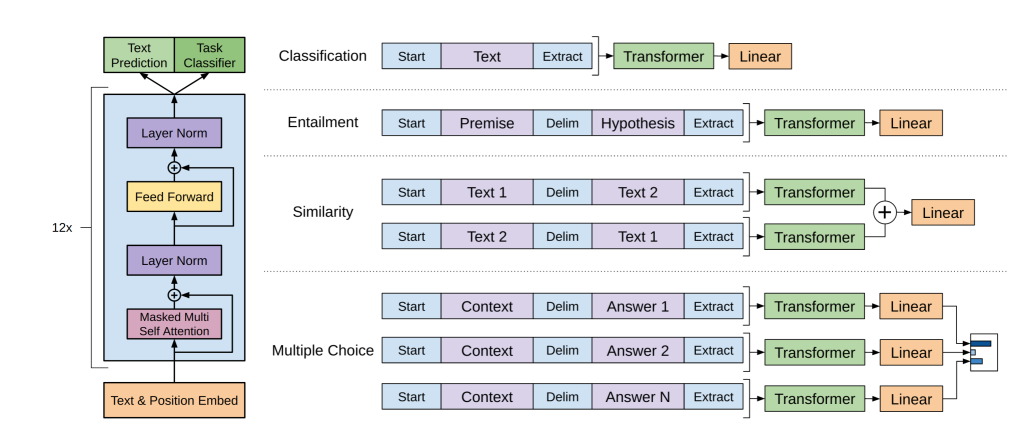
図1
図1は、この研究で使用されたトランスフォーマーアーキテクチャとトレーニング目標を示しています。左側の図は、トランスフォーマーアーキテクチャの構造とトレーニング目標を示しており、右側の図は、異なるタスクに対する微調整のための入力変換を示しています。すべての構造化された入力は、トークンシーケンスに変換され、事前トレーニングされたモデルで処理され、線形+ソフトマックス層に続きます。
3.3 Task-specific input transformations
テキスト分類などの一部のタスクでは、前述の方法でモデルを微調整することができます。しかし、質問応答や文脈推論などのように、構造化された入力が必要なタスクでは、事前トレーニングされたモデルを適用するために変更が必要です。このような場合、構造化された入力をトークンシーケンスに変換する必要があります。図1は、これらの入力変換を視覚的に示しています。すべての変換は、ランダムに初期化された開始トークンと終了トークン(〈s〉, 〈e〉)を追加することを含みます。
4.Conclusion
結論として、本研究では、大規模なトランスフォーマー言語モデルを事前トレーニングし、様々な自然言語処理タスクにおいて高い性能を発揮することができることが示されました。特に、本研究で提案された手法は、従来の手法よりも高い精度を達成し、長距離の文脈を効果的に扱うことができます。また、本研究では、異なるタスクに対する微調整のための入力変換方法も提案されています。これらの結果は、自然言語処理分野におけるトランスフォーマー言語モデルの有用性を示しています。