基本的なSequence-To-Sequenceモデルでは、エンコーダーネットワークは英語の文章を1つのベクトル\(h_T\)に圧縮し、デコーダーネットワークは\(h_T\)を基に、フランス語の文章を出力します。この基本的なSequence-To-Sequenceモデルには2つの問題があります。1つはエンコーダーの出力\(h_T\)が入力された英語の全文を表現するには小さすぎることです。2つ目は、デコーダーネットワークの各ステップの出力がエンコーダーの出力のどの部分に関係するのかを知る必要があることです。
Attentionの特徴
基本的なSequence-To-Sequenceモデルの問題を解決するため、2014年にAttentionという仕組みが提案されました。基本的なアイディアは、エンコーダーの内部状態\(h_1\), \(h_2\), ・・・, \(h_T\)の加重平均をデコーダーへ受け渡すことです。この加重(重み付け)の仕組みをAttentionと呼びます。デコーダーネットワークへより多くの情報を与えるこの仕組みは、Attention重み付けを利用して入力に関するより多くの気づきを得ることが出来ます。このAttentionを用いたSequence-To-Sequenceモデルを以下に示します。
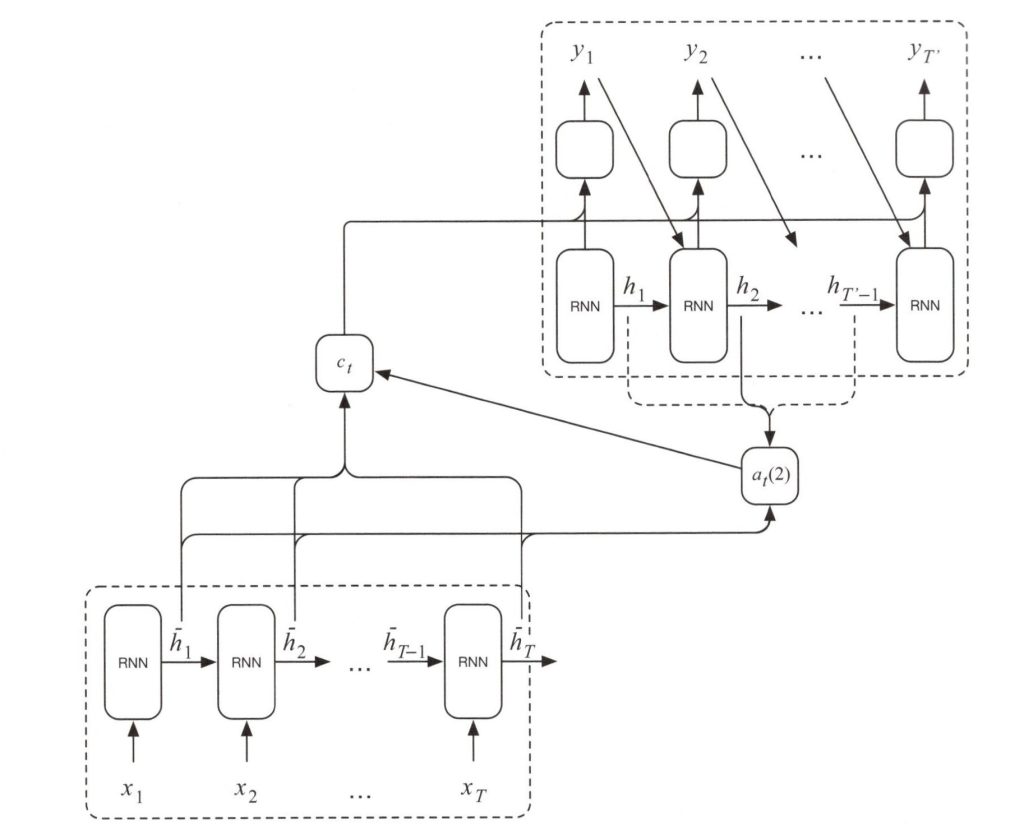
Attentionを用いたSequence-To-Sequenceモデル
具体的には上図では、Attentionの仕組みが\(a_t(S)\)層で実装され、エンコーダーの内部状態\(\vec{ h_1}\), \(\vec{ h_2}\), ・・・, \(\vec{ h_T}\)とデコーダーの内部状態\(h_t\)から英単語\(x_s\)からフランス語の単語\(y_t\)を生成する場合の重み(Attentional Weight)を生成します。\(a_t\)の計算式は次式のようになります。
\(\begin{eqnarray}
a_t(S)
=
\frac{exp(score(h_t,\vec h_s)}{\sum_{s’} exp(score(h_t,\vec h_{s’})} \tag{1}
\end{eqnarray}
\)
また、エンコーダーの内部状態は\(c_t\)層で実装され、エンコーダーの内部状態\(\vec h_{s}\)と関連付けられた\(a_t(S)\)により平均化されます。
\(\begin{eqnarray}
c_t = \displaystyle \sum_{s} a_t(s) \vec h_{s} \tag{2}
\end{eqnarray}
\)
デコーダーは\(c_t\)層で平均化された内部状態とデコーダーのRNNの内部状態\(h_t\)を\(softmax\)活性化関数による全結合層へ受け渡し、次式でフランス語の単語\(y_t\)の確率を推定します。
\(\begin{eqnarray}
y_t = softmax (W_y ✕ [c_t,h_t]) \tag{3}
\end{eqnarray}
\)