RNNネットワークの重要な応用例として、連続的な入力(Sequential Input)の意味を条件として、連続的な出力(Sequential Output)を生成するものがあります。具体例としては、日本語の文章から英語の文章への翻訳や人間とロボットの会話システムのための文生成などです。Sequence-To-Sequenceモデルは、このような目的でデザインされています。出力シーケンスは、入力シーケンスと1対1で対応付けられているわけではありません。この意味で、前述のRNN言語モデルとは異なります。
Sequence-To-Sequenceモデルの特徴
基本的なSequence-To-Sequenceモデルは、英語からフランス語へ翻訳するニューラル機械翻訳を構築する目的で、2014年に提案されました。このモデルは下図のように、エンコーダーネットワークとデコーダーネットワークと呼ばれる2つのRNNの変種からなります。
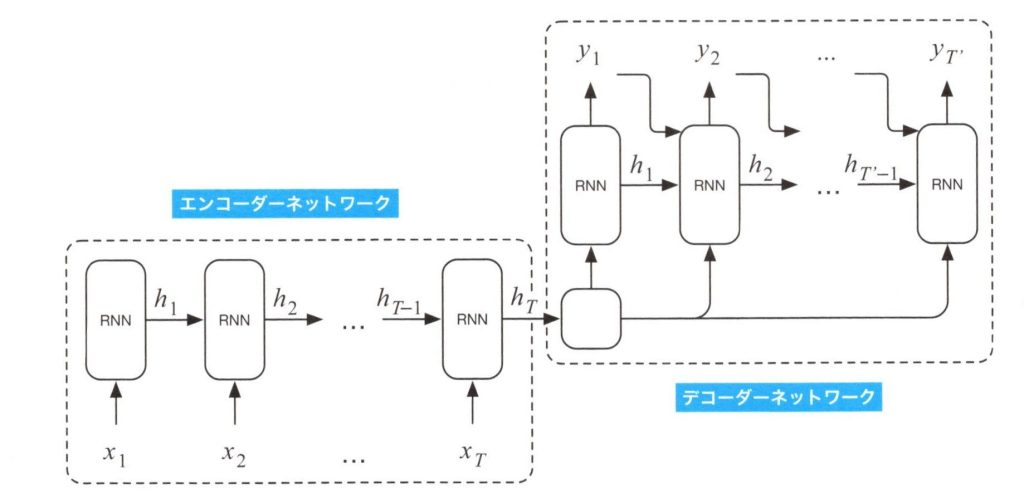
基本的なSequence-To-Sequenceモデル
上図の左下部分は、エンコーダーネットワークです。これは出力層を除いたRNNネットワークです。すべてのRNNネットワークが入力\(x_i\)と内部状態\(h_t\)を統合して、出力として\(h_T\)を生成します。このエンコーダーネットワークでは、\(x_i\)を入力シーケンスの英単語とし、RNNの内部状態\(h_t\)をそれ以前に入力された英単語の記憶に関連付けます。このエンコーダーネットワークの出力はベクトル\(h_T\)となります。
上図の右上の部分はデコーダーネットワークです。エンコーダーネットワークの出力\(h_T\)と、前ステップの出力\(y_{t-1}\)の2つの入力を取るRNNネットワークです。出力\(y_t\)はフランス語の単語とし、デコーダーネットワークは、\(T\)語の英文に対して\(T’\)語のフランス語の単語列を翻訳結果として出力します。デコーダーネットワークの最後の出力\(y_T’\)によって、出力語数\(T’\)が決定されます。もし、\(y_t\)が<END-OF-SENTECE>のような特別な終端文字であった場合は、タイムステップ\(t\)でRNNネットワークの出力は終了します。
・RNNの深さを増やす
もし十分なメモリを持ったGPUを利用できるなら、基本的なSequence-To-SequenceモデルのRNNの深さを増やすことができるため、下図に表される深層Sequence-To-Sequenceモデルのように、より性能の良い機械翻訳を実現できます。
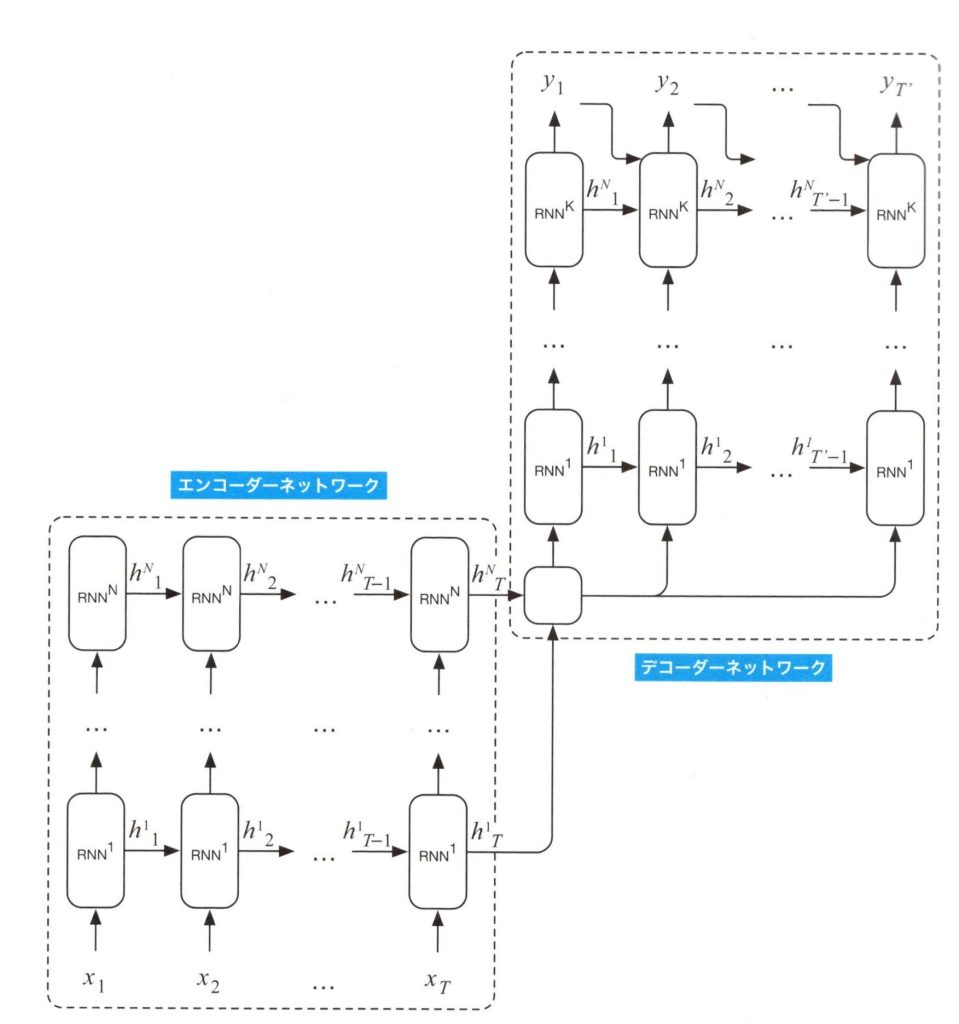
深層Sequence-To-Sequenceモデル